容器简介
基本概念
基本概念
历史简介
Docker项目最初由dotCloud公司发起,2013年开源,该项目的成功导致在2013年底dotCloud公司更名为Docker。 Docker使用Go语言开发,基于Linux的namespace+cgroup实现进程隔离控制,并通过容器镜像进行分发。 OCI(开放容器接口)协议包括运行时和镜像两部分内容,目前容器技术在实现上已不止docker一种,但基本都是遵守OCI规范的。
运行时在实现上最初基于LXC,之后为libcontainer,再演变为runC和containerd。其中runC就是OCI协议运行时部分的参考实现,containerd只是守护进程,向上提供统一gRPC接口。 containerd和runC已加入到CNCF(云原生)项目。
容器镜像可以看作是一层一层的数据,镜像本身都是只读的,在容器运行时,最上层(运行时层)是可写的,下面的(镜像层)仍然都是只读层。命令docker create执行完成就会生成一个可写层,供容器运行时使用。
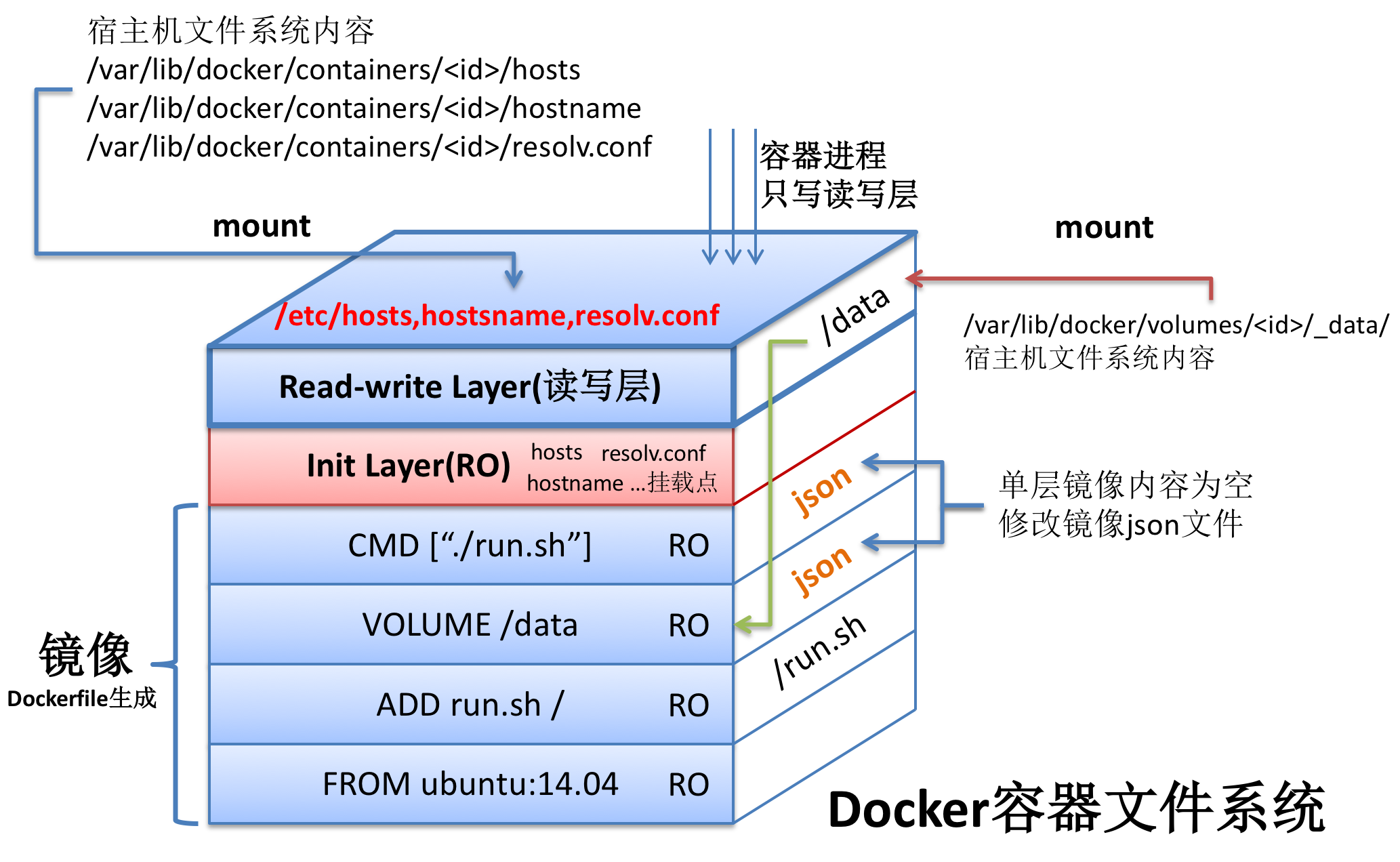
容器最核心的价值是打包应用环境,解决分布式系统运维问题。容器和镜像仓库可以很好解决单节点部署问题。但构建分布式运维平台,还需要编排、调度、伸缩、监控、容错、负载均衡、服务发现、滚动升级等诸多容器本身没有的功能。本文单讲容器相关内容。
docker
一个较为完整的容器功能包括客户端、服务端、镜像仓库、容器、镜像、网络。客户端供用户操作,服务端即daeon进程,镜像仓库用于分发镜像,剩下的容器、镜像和网络实际是三个驱动,docker在设计是采用接口加驱动的方法,可以在统一接口的前提下,在不同场景下使用不同的驱动。
在早期所有功能都集中在daemon中,后来由于标准化拆成多个组件,从docker-1.11开始已经有了containerd和runC组件。在不同版本,启动方法也有所不同。
| docker-1.8- | docker -d |
| docker-1.8 | docker daemon |
| docker-1.11 | dockerd |
细分后的模块:
- dockerd
- 容器守护进程,调用containerd管理容器生命周期,其他模块管理镜像存储等
- containerd
- 包括运行时和镜像管理,向daemon提供gRPC接口
- RunC
- RunC是按照OCF标准的具体实现,供containerd调用,负责容器起停和资源隔离等
namespace
Linux名字空间有六个,如下所示。
| CLONE_NEWNS | Linux 2.4.19 |
| CLONE_NEWUTS | Linux 2.6.19 |
| CLONE_NEWIPC | Linux 2.6.19 |
| CLONE_NEWPID | Linux 2.6.24 |
| CLONE_NEWNET | Linux 2.6.24 - Linux 2.6.29 |
| CLONE_NEWUSER | Linux 2.6.23 - Linux 3.8 |
创建进程调用clone()时指定相关标志位可以实现隔离,另外还有两个和名字空间相关的接口, setns用于加入到某个名字空间,unshare用于脱离某个名字空间。
USER名字空间用于实现在容器中看到的是root用户权限,但实际在宿主上并非root权限这样的功能,以提升安全性。
cgroup
控制组可用于限制容器所能使用的资源,如CPU、内存和磁盘等。控制组在功能上包括限制、审计、优先级和运行控制等。控制组在工作上按子系统划分,包括如下子系统,可以通过lssubsys来查看。
| cpu cpuacct cpuset | CPU控制、审计、独立CPU |
| memory | 内存限制 |
| blkio | IO限制 |
| net_cls net_prio | 网络等级、流量优先级 |
| devices | 设备访问 |
| freezer | 挂起或恢复任务 |
只需在cgroup/memory下创建一个目录就创建出一个memory的cgroup,该目录中会自动创建出所需文件。
fs
容器镜像基于分层的思想构建,实现这些分层理念,需要用到UnionFS,而UnionFS在具体实现起来又有很多方法,因而出现了不同的存储驱动方案。
容器存储会用到COW(写时复制)技术,多个进程共享同一份文件,当有进程要写入时,把要写入的部分复制给进程用于写入,这样可以让所有程序共享镜像层。
容器在实现上都是采用抽象接口加底层驱动的方式来做的,驱动分三类:运行时、存储、网络。
主要存储驱动如下所示:
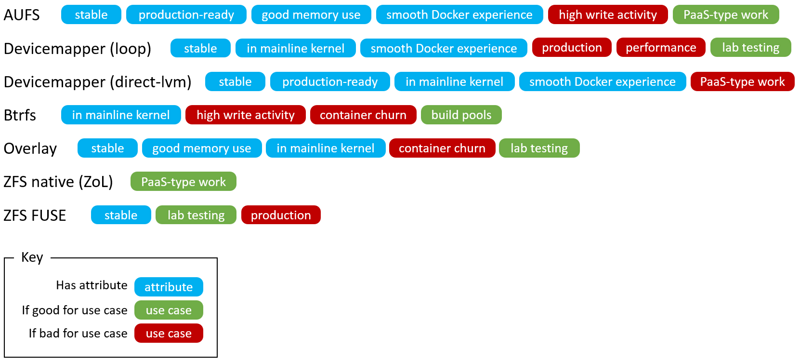
另外需要注意docker-1.10对镜像存储驱动做了大改,原来的层ID是随机生成的,修改后基于内容SHA256计算,这样做的目的是借助CAS(Content Addressable Storage)提升安全性,可以在拉取或推送镜像时进行完整性校验。
- DeviceMapper
DeviceMapper基于Linux内核的Device Mapper框架实现。该框架实现了物理设备与虚拟存储的映射,或虚拟设备与虚拟设备的映射。基于该框架可以实现磁盘自由划分,如LVM2、software RAIDs、dm-cryptdisk encryption等。 Device Mapper框架提供两个功能:thin-provisioning和snapshot。
- thin-provisioning
- 类似虚拟内存,提供给使用者的空间只有在使用者进行写操作时才真正进行分配。假设使用者有一块100g的thin块设备,使用了20g,实际系统提供的大小就是20g,只有当使用者进行存储操作时才分配更多的空间,直到100g。
- snapshot
- 快照是一种COW策略的实现,假设从A设备做快照得到B设备时,并未对A进行完整拷贝,而是当对B设备进行写操作时,才将需要改变的那部分做属于B设备的拷贝。
DeviceMapper借助thin-provisioning和snapshot实现了镜像的分层结构和存储优化。
在用devicemapper作为驱动的docker中,每个镜像和容器都对应一个设备,通过对镜像做snapshot操作得到容器,所以容器中拥有镜像的内容且操作这些内容不影响镜像本身,因为容器和镜像对应不同的设备。
DeviceMapper的大致思路是,先通过虚拟化技术得到一个thin-pool设备(可理解成一个资源池),接着在thin-pool上建立一个基础设备,此后docker上所有镜像和容器都是基于此设备的snapshot。
DeviceMapper有两种模式可选,loop-lvm和direct-lvm。两个模式的区别就在建立thin-pool的方法不同。
loop-lvm:不推荐用于生产环境,容器数量增大时性能急剧下降
- 创建两个稀疏文件data和metadata
- 将这两个文件映射成两个块设备(loopback块设备)
- 将两个设备通过内核中Device Mapper映射成thin-pool
direct-lvm:利用了基于Device Mapper的LVM
- 将空余块设备(可以是分区)创建成physical volume(pv)
- 在由这些PV组成volume group(vg)
- 从vg中建立两个logical volume(lv),data和matedata
- 将data和matedata映射成thin-pool
可通过lsblk查看设备信息,loop-lvm可以看到是loop设备,而direct-lvm为块设备。
- OverlayFS
OverlayFS和Aufs相比主要是设计上更简单并在linux-3.18加入到了内核中。由于OverlayFS只工作在两层,比Aufs的多层查询性能也会好点。也支持页缓存,多个容器共享页,高效利用内存。
目前docker搞了两个基于overlayfs的存储驱动,overlay2驱动对inode性能做了优化,原生支持多层镜像(最大128),但是只支持linux-4.0以上的版本。
OverlayFS在设计上只有两层,镜像在底层,容器运行时在上层,统一出来就是合并层。创建一个容器时,overlay驱动将合并层提供给容器使用。
这就是说多层镜像不能对应多层OverlayFS,而是使用一个目录来表示一个层,并利用硬链接技术来引用底层数据。镜像数据存储在
/var/lib/docker/overlay2目录下。- 读取时,从上层开始找,找到就读取,否则就找下层。
- 写入时,如果上层有文件就直接写,没有就复制下层到上层再写入。
- 删除时,通过创建特殊文件或目录表示文件或目录已删除。
- 重命名,只允许原路经和目标路径都在顶层才能操作,否则返回EXDEV
注意事项:
- overlay驱动会消耗大量inode,overlay2不存在此问题
- 首次写入引发的向上复制,大文件会增加复制负担
- open:对同一个路径的文件打开,指定模式不同(RO/RW),实际指向的文件可能会不一样
- rename:和aufs一样,只能顶层之间的路径相互重命名
目前overlayfs是存储驱动首选。
镜像仓库
构建镜像
FROM ubuntu:14.04.2 # 基准镜像 MAINTAINER mickyching@gmail.com # 作者 ARG Name=micky # ARG仅在构建镜像时有效 ENV GOPATH=/home/go GOROOT=/home/go # ENV在容器运行时也有效 LABEL Owner=$Name # 标签 RUN useradd -m micky && apt-get update # 执行命令 USER micky # 切换用户 WORKDIR /home/micky # 切换工作目录 COPY calc.py ./ # 复制文件 VOLUME /data # 挂载目录,位于:/var/lib/docker/volumes/ EXPOSE 22 # 暴露端口 CMD [1+1] # 启动命令 ENTRYPOINT ["./calc.py"] # Init程序
要点:
- 尽量减少ENV和RUN的调用次数,这样可以减少镜像层数
- 在VOLUME指令后对其目录的写入操作都不会记录到镜像
- 在一个干净的目录中执行build命令,因为构建是会将整个目录发送给daemon
docker build -t calc . # 编译 docker run --rm calc '1+1' # 运行
root@f38c87f2a42d:/# mount ... /dev/disk/by-uuid/1fec...ebdf on /etc/hostname type ext4 ... /dev/disk/by-uuid/1fec...ebdf on /etc/hosts type ext4 ... /dev/disk/by-uuid/1fec...ebdf on /etc/resolv.conf type ext4 ... ...
不要在容器镜像中修改这些配置,而应该启动容器时通过命令行指定相关参数。
harbor
有了镜像之后就面临一个存储和分发的问题,除了使用共有镜像仓库,也可以搭建私有镜像仓库,私有仓库体验上更快更安全。
这里讨论如下几个问题:
- 数据存储如何管理
- 安全认证如何实现
- 如何提升可用性
- 如何跨地域
- 数据存储
在存储方面,docker开源了distribution,用于实现镜像仓库的存储。
- 认证授权
在帐号方面,可以使用vmware开源的harbor。为了使harbor和自身帐号系统相通,需要改动认证相关的代码,来实现认证和鉴权。如何觉得harbor自带的UI不满足要求,还可以独立设计UI,这是也是目前很多公共镜像仓库的做法。
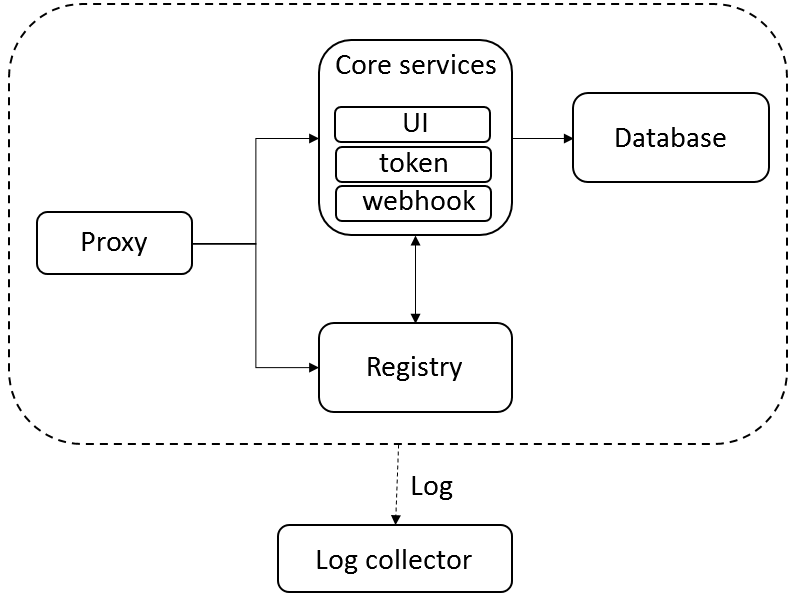
Harbor的主要模块如上图所示,功能如下:
- proxy 即nginx反向代理
- registry 即docker开源的distribution
- UI 是harbor的核心服务,提供认证和界面
- DB 数据库可用mysql服务
- log 用rsyslog收集日志
为了跟进一步说明harbor工作原理,这里以docker login为例说明:
- docker login url 发出请求到url:443(或url:80)
- proxy收到请求,代理给registry
- registry服务那里配置了token服务地址,返回401错误和token服务地址
- docker客户端向token服务地址发送用户名和密码请求token
- proxy将请求代理给token服务
- token服务校验成功后生成token并返回
- 登录成功后,docker会把用户名和密码保存在本地
其他操作和docker login一样,如docker push操作过程如下:
- 重复docker login过程,发送请求到proxy,代理到registry,进而得到token服务地址
- docker向token服务请求token,这里会提供额外信息,指明操作类型(push/pull)和对象(image)
- 请求通过proxy代理给token服务,服务进行认证和鉴权,鉴权成功就返回token
- docker得到token后,向registry发出推送请求,registrya验证token后开始传输
Harbor的每个项目有三种角色:管理员、开发、访客。管理员可以管理帐号,开发可以读写仓库,访客只能读仓库。
- 高可用性
可用性提升一般采用LB负载均衡实现,即LB后面可以挂多个Harbor,这些Harbor本身无状态,至于数据部分采用共享存储,如多个Harbor共享一块网盘,这里还需注意共享存储一般只用于一个地域。负载均衡方法还需要考虑用户session如何在多实例上共享,如使用redis进行共享。
- 跨域同步
最后一个问题是在地域规模扩大时,如何提升镜像仓库的性能和可用性。
主从模式可以有效解决分发问题,写入还是直接写到中央数据中心。对于分发地域较广的情况,可以在此基础上增加分层,通过多级分层以减少中央分发压力。
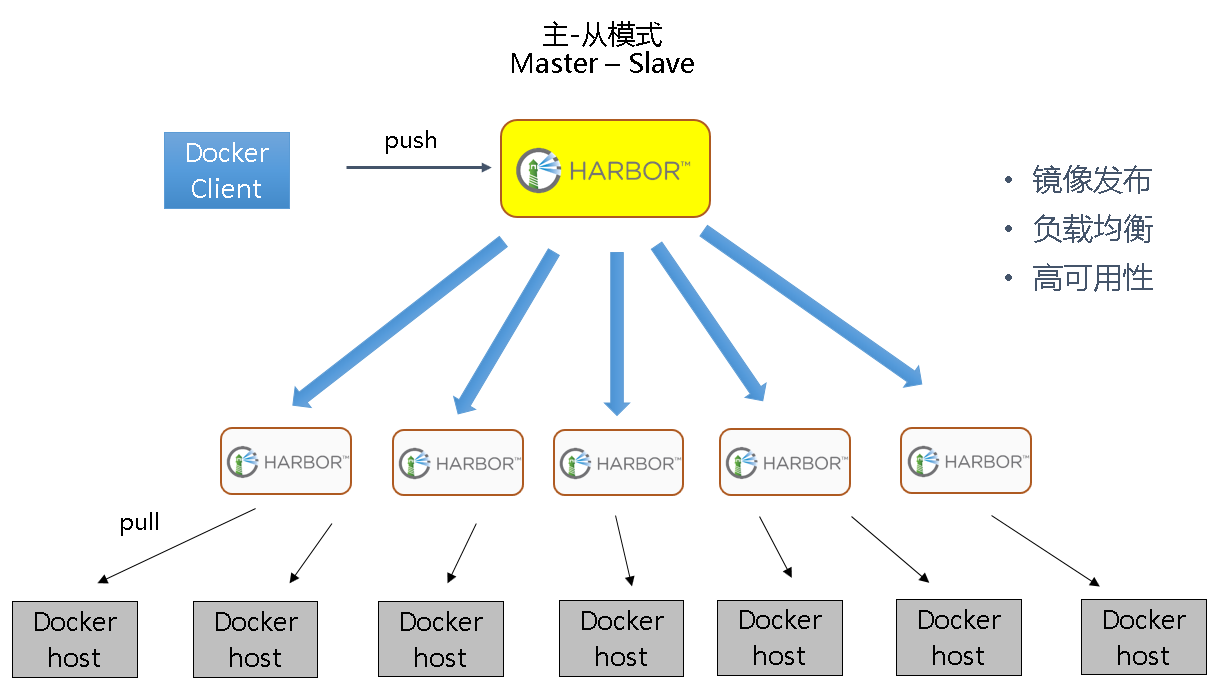
如果镜像被删除,缓存节点是如何知道被删除或者有更新,确保缓存可以得到最新的镜像。
采用这种分级的方式仍然不能解决写入问题,对于跨境仓库,需要多数据中心,单个数据中心会导致境外上传缓慢。跨中心复制可以用Job Service组件,Job Service会将执行进度更新到DB中,用户可以查看进度。实现上接收API请求并调度任务,但是要考虑如何限流以及如何干预复制过程(如取消、重试)。
复制是针对项目来手动触发的,一般不做跨数据中心自动同步。
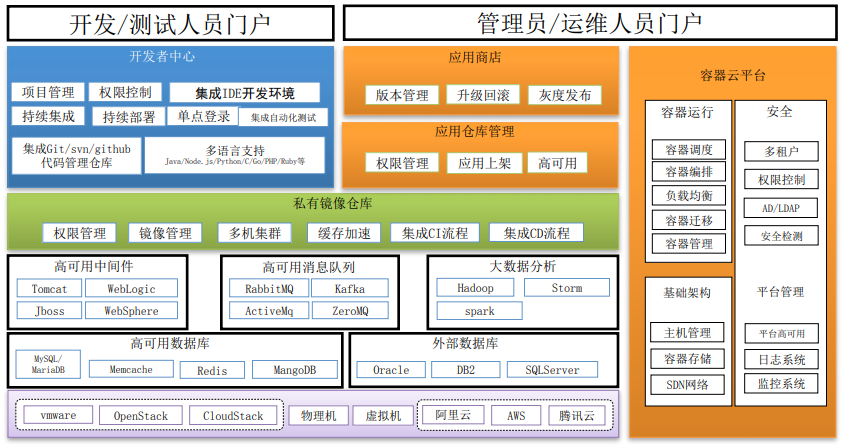
容器云
微服务
微服务
- 什么是微服务
微服务是一种高内聚、松耦合的架构风格。
- 微服务的好处
- 敏捷开发:技术栈灵活,可以应对需求频繁变更
- 敏捷发布:独立部署,没有依赖,不用完整编译一个完整单体发布
- 伸缩性好:水平扩展、按需扩展
- 鲁棒性好:可用性高
- 减少冗余:减少代码、模块、功能冗余
- 微服务的问题
- 技术栈灵活导致环境复杂:该问题由docker天生解决
- 服务规模上升导致发布复杂:需要编排支持,可由kubernetes解决
- 全局监控
- 分布式问题追踪
- 资源竞争时如何处理:如优先级控制
- 完整体系支撑:如网络、存储等
- 微服务的需求
- 安全 登录 鉴权 隔离
- 文档 仓库 部署 编排 集成 测试 终端
- 注册 发现 均衡 伸缩 升级 灰度 回滚
- 过滤 流控 熔断 降级 容错 灾备
- 日志 聚合 监控 汇聚 检查 恢复 告警
- 网络 存储
参考资料
- DOCKER基础技术:LINUX NAMESPACE(上)
- DOCKER基础技术:LINUX NAMESPACE(下)
- DOCKER基础技术:LINUX CGROUP
- DOCKER基础技术:AUFS
- DOCKER基础技术:DEVICEMAPPER
- 容器和存储驱动
- OVERLAYFS简介
- Docker存储方式选型建议
- 深入了解Docker存储驱动
- Docker存储驱动性能测试
- Docker、Containerd、RunC…:你应该知道的所有
- Dockerfile 参考文档
- Docker compose file 参考文档
- 直击阿里双11神秘技术:PB级大规模文件分发系统“蜻蜓”
- 如何把Docker镜像分发速度提升90%
- 微服务容器化的挑战和解决之道
- 微服务架构探讨
- 从单体架构到微服务的服务化演进之路