容器网络
容器网络
单节点网络
单节点网路
- 桥接模式
原本网桥用于连接不同的LAN,组成更大的LAN,网桥负责转发和学习二层广播包。
容器网桥用到两个技术,虚拟网络接口和NAT(网络地址转换)。虚拟网络接口对用于将容器中的VETH和网桥中的VETH绑定并实现数据互通。 NAT技术又包括DNAT和SNAT,DNAT是替换目标地址,SNAT是替换源地址。容器和外部通信时要用NAT技术绑定容器和宿主端口,由宿主IP:PORT+NAT和外部通信。外部服务响应时容器时不需要走DNAT,而是通过iptables转发。
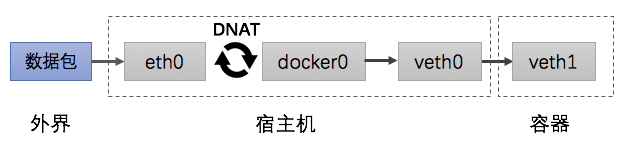

容器网桥的问题:
- 无法对外暴露容器IP,宿主机和VETH不在一个网段
- 由于NAT在三层网络实现,传输效率较低
- 主机模式
直接使用主机相同的网络栈,没有隔离网络环境
- 容器模式
多个容器共用一个网络环境,共享网络名字空间
- NONE模式
容器只有一个loopback网络设备
跨节点网络
Overlay
Overlay网络无需改造网络架构,只需三层可达即可,将二层报文封装在IP报文中。这样能利用成熟的IP路由协议进行数据分发,采用隔离标识能够突破VLAN的数量限制,必要时把广播流量转化为组网流量避免广播数据泛滥。因此Overlay网络是最主流的容器跨节点路由和数据传输方案。
Overlay网络的实现方式有多种,IETF制定了三种实现标准: VxLAN(虚拟可扩展LAN)、NVGRE(通用路由封装虚拟化网络)、SST(无状态传输协议)。其中VxLAN已成为Overlay网络的事实标准。在这三种标准以外,还有许多不成标准的Overlay通信协议,例如Flannel、Calico、Weave等工具都包含了一套自定义的Overlay网络协议,其中Flannel也支持VxLAN模式。这些自定义的网络协议通信效率远低于IETF的标准协议。
Overlay主要分为L2/L3、L3/L3、L2/UDP、L3/UDP几种。
- L2/L3
- 可以跨机迁移不改变IP;不同租户IP可以重叠;容器IP可以和底层网络重叠
- L3/L3
- 容器跨机迁移可能要改变IP地址,取决于上层L3是平面还是分层网络
- VxLAN
VxLAN后端本质上是在三层网络上构建二层网络,只不过利用内核原生支持。该模式下的插件有:docker-vxlan、flannel-vxlan等。
flannel-vxlan工作原理:
- flanneld先于docker启动,划分子网并在etcd中注册
- 启动docker,读取flannel配置以配置bip等信息,实际给容器分配IP由docker完成
- vtep网桥管理整个网络,docker0只管理本机子网
- 数据由内核转发,flanneld只需动态更新arp
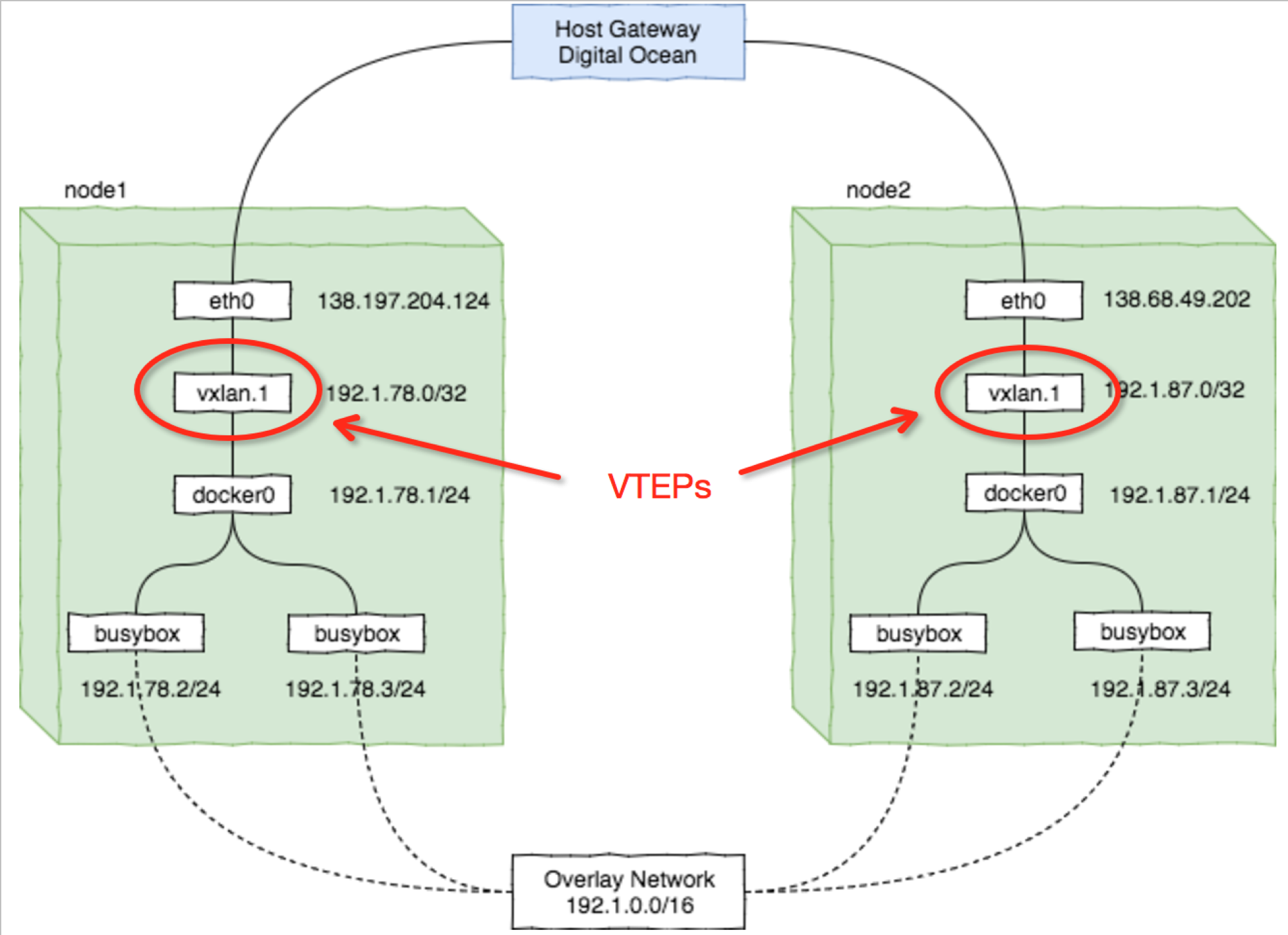
VxLAN的优点:
- 数据由内核转发,性能较高
- flanneld短暂停止不会中断网络
- 只需主机三层可达
VxLAN的问题:
- 依赖存储服务
- 需要为每个主机分配一个网段,用于给容器分配IP
- 迁移容器无法保持IP不变,因为每个主机的网段不一样
- 容器和主机不能直接通信
- 无法暴露容器IP,暴露容器服务仍然需要端口映射
- UDP
UDP后端也是在三层网络上构建二层网络,只不过使用UDP封包,不需要内核支持。该模式下的插件有:flannel-UDP、weave-UDP等,这种模式主要用于早期内核,因为早期内核不支持VxLAN。数据的封包和解包由后台进程处理,使得该模式性能很差。
Underlay
Underlay网络由底层网络驱动将接口暴露给虚机或容器,两个驱动分别是MACVLAN和IPVLAN,比桥接和Overlay更简单高效。
- MACvLAN
MACVLAN允许在主机的单个物理接口后面创建多个虚拟网络接口,每个虚拟接口具有唯一的MAC和IP地址分配。容器IP地址和物理接口必须在相同的广播域,MACVLAN每个容器使用唯一的MAC地址。
MACvLAN的问题:
- 如果一个容器消耗一个mac,对mac的消耗会很大,而网络接口和交换机对mac的支持有上限。 NIC一般限制512个MAC。
- IP地址需要在与物理接口相同的广播域
- 主机和容器完全隔离,容器不能和宿主通信
- 不能用于存在防MAC欺骗交换机的网络
- 当mac地址过多时会造成严重的性能损失
- 无法和802.11(wireless)网络一起工作
- 搭建复杂网络拓扑时,如要和BGP网络一起工作,不能使用macvlan
- 容器不能与宿主通信
- IPvLAN
IPVLAN与MACVLAN类似,它创建新的虚拟网络接口并为每个IP地址分配一个唯一的IP地址,但他们的MAC和宿主机相同。
IPVLAN可以在L2或L3模式下运行:
L2模式下父接口作为交换机转发子接口的数据,该模式要求容器IP和宿主IP在同一个子网。 L2模式下,ipvlan虚拟网卡能够收到广播报文,能够自己处理arp请求。
L3模式要求容器IP和宿主IP在不同的子网。网络堆栈在容器内处理,不允许多播或广播流量。在这个意义之上,如同L3路由器的行为, ARP请求由主网卡代为处理。 L3模式在发送数据包时不一定会走ipvlan宿主设备,可能通过路由走其他设备发送出去。
L3s模式跟L3模式唯一的区别在于,L3s模式只有在报文是发往本地的时候才修改接收数据包的网卡,否则不修改,这种模式没法和tap设备结合。
路由方案
路由方案通过路由配置实现容器跨主机通信,每个容器像虚拟机一样分配一个业务IP。路由网络对现有网络设备影响比较大,路由器的路由表限制一般是两三万条。而容器的大部分应用场景是运行微服务,数量集很大。如果几万新的容器IP冲击到路由表里,导致下层的物理设备没办法承受;而且每一个容器都分配一个业务IP,业务IP消耗会很快。
Calico-BGP模式正是使用的路由方案,基于BGP协议,通过三层路由实现跨主机通信。 Calico-BGP模式包括三个组件,etcd存储、felix配置路由、BIRD分发路由。 BIRD有两种模式,网格模式用于小规模,集中模式用于大规模。
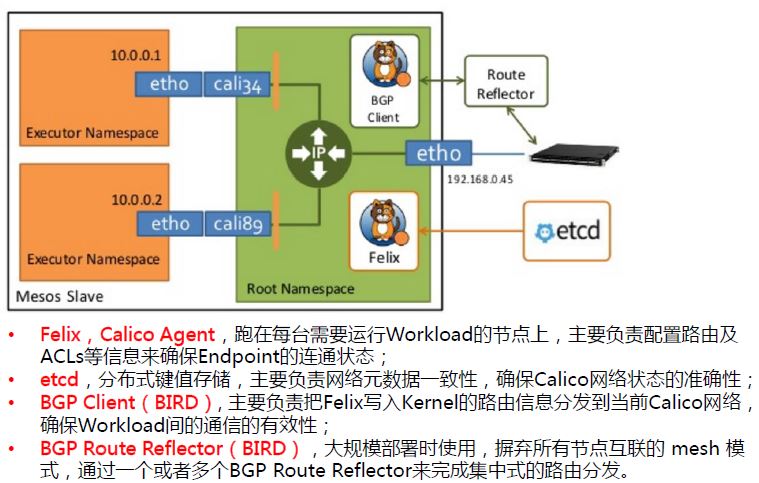
Calico-BGP模式优点:
- 可以暴露容器IP
- 容器漂移IP不变
- 不需要NAT或隧道,性能高
Calico-BGP模式主要问题:
- 相关组件会在主机上生成大量路由表,路由数目和容器数目相同,超出路由器、三层交换、节点处理能力
- 节点上配置大量iptables,难以排障
- 不支持VPC,容器只能从calico网段中获取IP
- 没有流量控制,存在少数节点抢占多数带宽
二层VLAN
二层VLAN就是将网络架构改造成互通的大二层网络,效率上比Overlay高。
二层VLAN主要问题如下:
- 需要二层网络设备支持,不够通用和灵活
- 交换机的可用VLAN数量限制在4096个(LANID长度12位)
- 大型数据中心使用VLAN会造成广播数据泛滥,影响带宽
- 不同租户的IP不能重叠
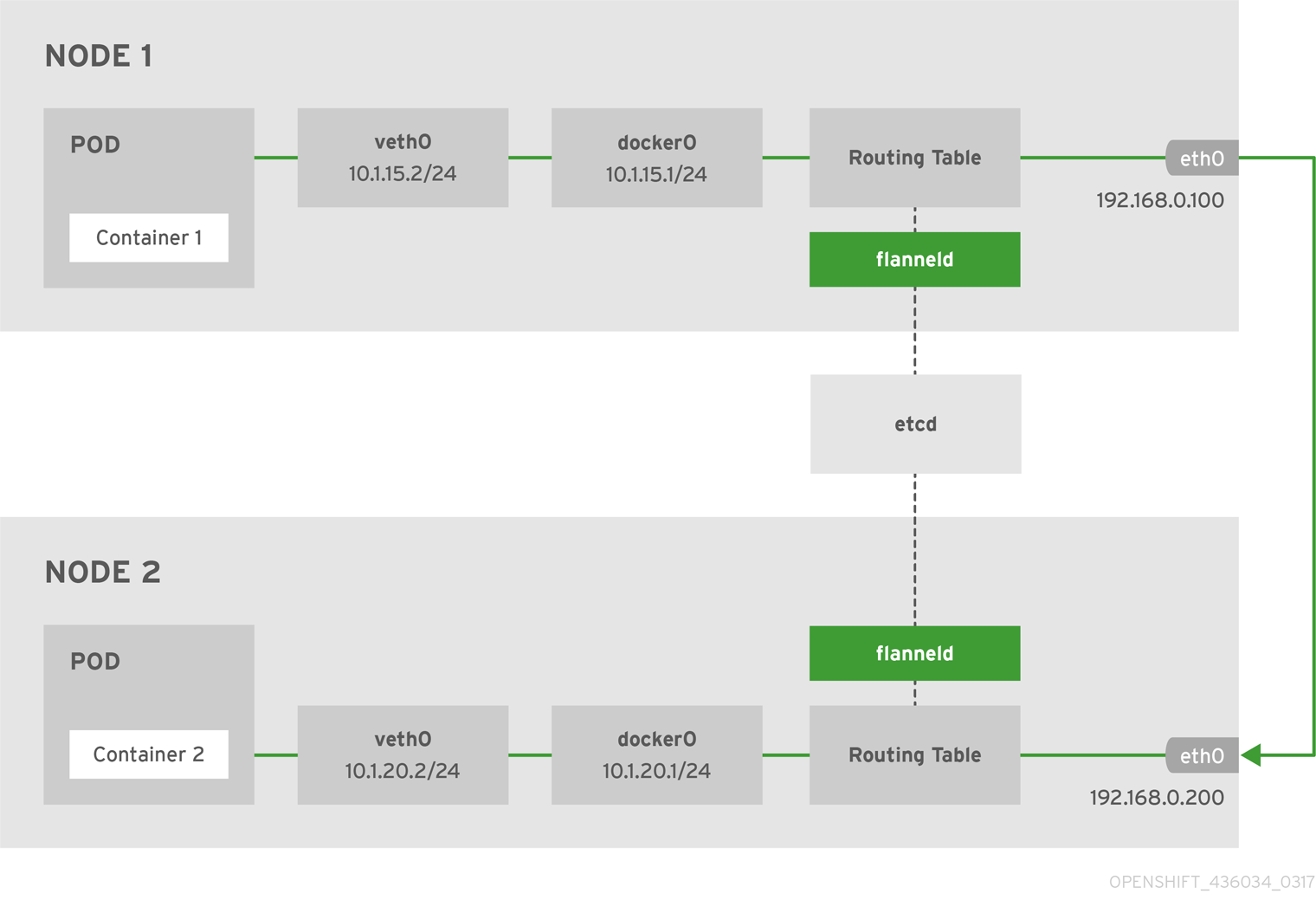
Kubernetes
Pod与Pod间接通信:每个节点都有kube-proxy,它会从kube-apiserver拉取配置信息,动态更新节点上的iptables,Pod访问service时会根据iptables转发到具体的Pod。
Pod与Pod直接通信:利用网络插件实现数据转发。
间接通信实际上会在每个节点配置大量的iptables规则,服务数量增多时,性能损失也较大。直接通信通常用overlay网络插件,依赖外部存储,性能也比较差。
Kubernetes的服务只能集群内部可见,也就是利用kube-proxy查找。要暴露到外部,需要用NodePort模式,这需要在每个节点上映射一个相同的端口。所以kubernetes单独定义了一个Ingress对象,用于支持L4/L7负载均衡,基于Pod部署,后端为服务名和端口,网络设置成外部网络,支持haproxy/nginx/GCE-L7控制器,由于Ingress基于Pod部署,可能会发生IP漂移。还需要额外手段保持Ingress本身的高可用。