Linux虚拟文件系统源码分析
Table of Contents
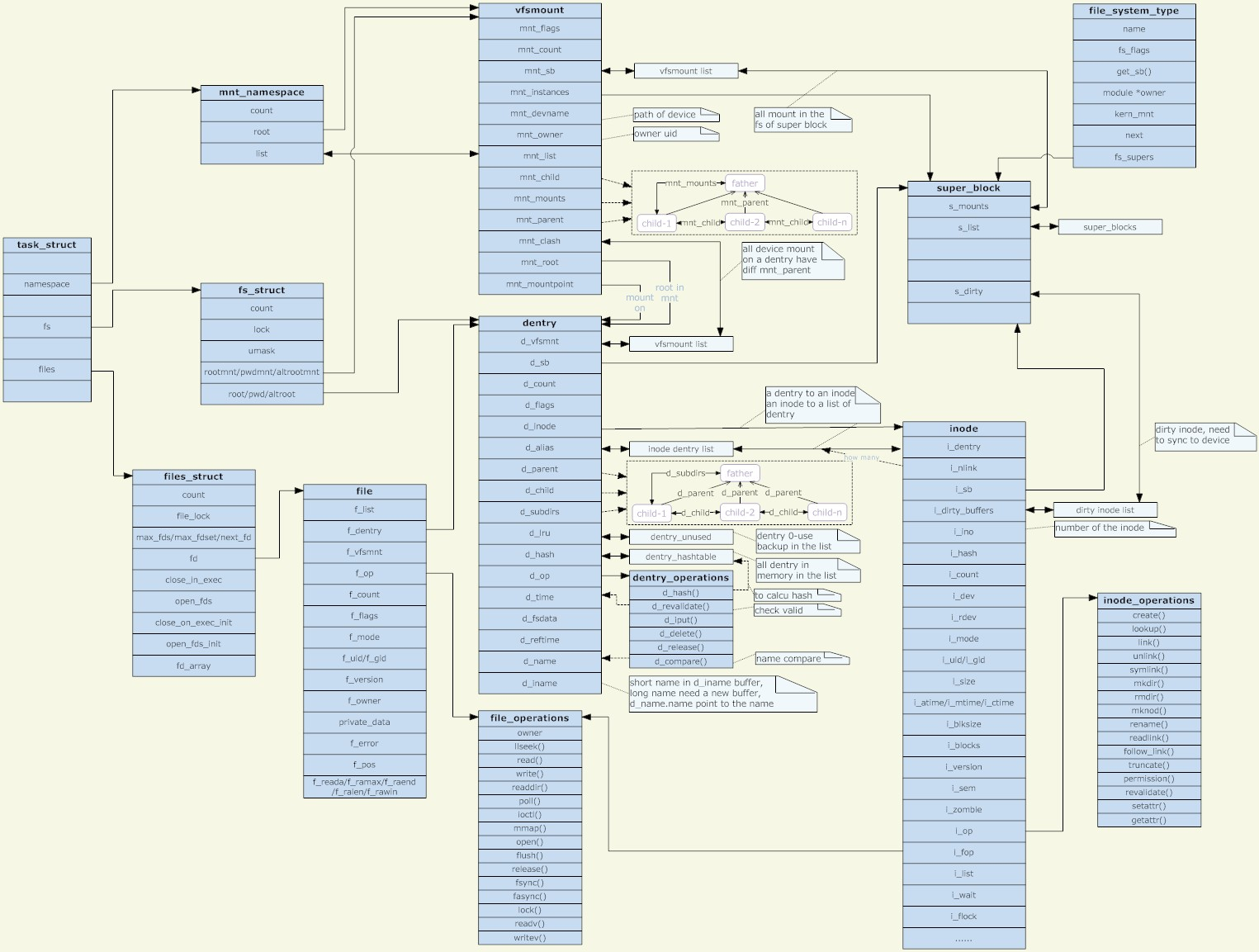
数据结构
VFS中关联的数据结构很多,如下图所示。在这里我们先把核心要素说明一下,基本上都是按照面向对象的思路来设计的,而最重要的要素就是超级块、索引节点、文件和目录项。
这里会介绍文件描述符到文件的转换,索引节点和目录项哈希表的基本操作,并以根文件系统为例说明文件系统的注册与挂载操作。此外还包括文件名查询代码的分析,以及文件访问操作等。
超级块
super_block
struct super_block { struct list_head s_list; // super_blocks & sb_lock dev_t s_dev; // MKDEV() struct block_device *s_bdev; unsigned long s_blocksize; // 512 or 2**n unsigned char s_blocksize_bits; // log2(s_blocksize) loff_t s_maxbytes; // MAX_LFS_FILESIZE struct file_system_type *s_type; const struct super_operations *s_op; const struct dquot_operations *dq_op; const struct quotactl_ops *s_qcop; const struct export_operations *s_export_op; unsigned long s_flags; #define MS_RDONLY 1 // 只读 #define MS_NOSUID 2 // 忽略GID和UID #define MS_NODEV 4 // 不允许访问设备特殊文件 #define MS_NOEXEC 8 // 不允许执行程序 #define MS_SYNCHRONOUS 16 // 写入立即同步 #define MS_REMOUNT 32 // 更改挂载标志 #define MS_MANDLOCK 64 // 允许对FS强制锁住 #define MS_DIRSYNC 128 // 目录更改立即同步 #define MS_NOATIME 1024 // 不更新访问时间 #define MS_NODIRATIME 2048 // 不更新目录访问时间 // ... unsigned long s_magic; // 验证磁盘信息 struct dentry *s_root; // root dentry struct rw_semaphore s_umount; // 读写期间防止umount int s_count; // get_super()/put_super() atomic_t s_active; // grab_super(), freeze_super() // deactivate_super() const struct xattr_handler **s_xattr; struct list_head s_inodes; // 所有的索引节点链表 // inode->i_sb_list // inode_sb_list_lock struct hlist_bl_head s_anon; // 远程网络文件系统的匿名目录项链表 struct list_head s_mounts; // 所有挂载点 // mount->mnt_instances // mount_lock struct backing_dev_info *s_bdi; struct mtd_info *s_mtd; struct hlist_node s_instances; // 文件系统实例节点 // file_system_type->fs_supers // sb_lock struct quota_info s_dquot; struct sb_writers s_writers; char s_id[32]; // 设备名 u8 s_uuid[16]; void *s_fs_info; // 指向具体文件系统的信息 unsigned int s_max_links; // 最大硬链接数 fmode_t s_mode; // 文件操作权限 u32 s_time_gran; // 时间精度ns,最大为1s // 只有VFS会使用这个互斥锁,具体文件系统的代码不能使用 // 这个锁用于防止把一个目录重命名为它的子目录 struct mutex s_vfs_rename_mutex; // 子类型,在/proc/mounts显示格式为"type.subtype" char *s_subtype; char __rcu *s_options; // 传递给mount()的data const struct dentry_operations *s_d_op; // dentry的默认操作集 // 缓存池ID,-1表示没有缓存池 // 只有ext3、ext4和btrfs文件系统支持这个特性 int cleancache_poolid; struct shrinker s_shrink; // number of inodes with nlink == 0 but still referenced atomic_long_t s_remove_count; // being remounted read-only int s_readonly_remount; // AIO completions deferred from interrupt context struct workqueue_struct *s_dio_done_wq; // dentry的lru链表,节点为dentry->d_lru struct list_lru s_dentry_lru ____cacheline_aligned_in_smp; // inode的lru链表,节点为inode->i_lru struct list_lru s_inode_lru ____cacheline_aligned_in_smp; struct rcu_head rcu; };
相关函数:
- sget
- 构造函数,如果没有从已经挂载的文件系统找到需要的
super_block就会调用alloc_super分配一个 - put_super
- 析构函数,当引用计数减少到0时才会调用
destroy_super真正释放
super_operations
主要包括对inode数据结构的操作,注意不是对inode的操作,对inode的操作由inode_operations来完成。如:alloc_inode、destroy_inode、dirty_inode等等。
还包括文件系统挂载和卸载等操作,如:sync_fs、statfs、remount_fs等等。
所有的函数由VFS调用,都在进程上下文调用,所有的函数都可能阻塞。
索引节点
inode
struct inode { umode_t i_mode; // 访问权限 unsigned short i_opflags; // 用于标识具备那些操作 #define IOP_FASTPERM 0x0001 // 没有permission() #define IOP_LOOKUP 0x0002 // 具有lookup() #define IOP_NOFOLLOW 0x0004 // 没有follow_link() unsigned int i_flags; #define S_SYNC 1 /* Writes are synced at once */ #define S_NOATIME 2 /* Do not update access times */ #define S_APPEND 4 /* Append-only file */ #define S_IMMUTABLE 8 /* Immutable file */ #define S_DEAD 16 /* removed, but still open directory */ #define S_NOQUOTA 32 /* Inode is not counted to quota */ #define S_DIRSYNC 64 /* Directory modifications are synchronous */ #define S_NOCMTIME 128 /* Do not update file c/mtime */ #define S_SWAPFILE 256 /* Do not truncate: swapon got its bmaps */ #define S_PRIVATE 512 /* Inode is fs-internal */ #define S_IMA 1024 /* Inode has an associated IMA struct */ #define S_AUTOMOUNT 2048 /* Automount/referral quasi-directory */ #define S_NOSEC 4096 /* no suid or xattr security attributes */ // attrs: i_uid, i_gid, i_atime, i_mtime, i_ctime const inode_operations *i_op; const file_operations *i_fop; struct super_block *i_sb; address_space *i_mapping; unsigned long i_ino; dev_t i_rdev; const unsigned int i_nlink; loff_t i_size; // 文件大小,字节数 blkcnt_t i_blocks; // 文件大小,块数 unsigned int i_blkbits; // 块的位数,从sb继承 spinlock_t i_lock; // protect i_state unsigned short i_bytes; // bytes consumed unsigned long i_state; #define I_DIRTY_SYNC (1 << 0) #define I_DIRTY_DATASYNC (1 << 1) #define I_DIRTY_PAGES (1 << 2) #define __I_NEW 3 #define I_NEW (1 << __I_NEW) #define I_WILL_FREE (1 << 4) #define I_FREEING (1 << 5) #define I_CLEAR (1 << 6) #define __I_SYNC 7 #define I_SYNC (1 << __I_SYNC) #define I_REFERENCED (1 << 8) #define __I_DIO_WAKEUP 9 #define I_DIO_WAKEUP (1 << I_DIO_WAKEUP) #define I_LINKABLE (1 << 10) #define I_DIRTY (I_DIRTY_SYNC | I_DIRTY_DATASYNC | I_DIRTY_PAGES) struct mutex i_mutex; unsigned long dirtied_when; // jiffies struct hlist_node i_hash; // inode_hashtable struct list_head i_wb_list; struct list_head i_lru; // sb->s_inode_lru & inode->i_lock struct list_head i_sb_list; // sb->s_inodes // inode_sb_list_lock union { struct hlist_head i_dentry; // 所有引用该节点的dentry // dentry->d_alias struct rcu_head i_rcu; }; u64 i_version; atomic_t i_count; // iput() atomic_t i_dio_count; // direct io count atomic_t i_writecount; // 有多少个用户对该节点有写权限 struct file_lock *i_flock; struct address_space i_data; struct list_head i_devices; union { struct pipe_inode_info *i_pipe; struct block_device *i_bdev; struct cdev *i_cdev; }; __u32 i_generation; // 索引节点版本号 void *i_private; // private pointer };
- i_nlink
- 硬链接数,虽然这里显示为const,实际上是可以改变的,设计为union,可以用(set/clear/inc/drop)_nlink() 或inode_(inc/dec)_link_count()修改
- i_version
- 用来记录索引节点的改变,例如我们用编辑器打开一个文件,里面的数据缓存在file中,当另外一个程序修改文件以后,编辑器就会提示我们,磁盘上的文件已经被修改,我们可以强制覆盖,也可以从磁盘重新读取。
- i_devices
- 之所以用链表而不是单个对象,是因为我们可以为同一个设备创建多个设备节点,用mknod就能做到。另外chroot环境会使得一个设备通过多个设备文件。
相关函数:
- new_inode
- 构造函数,调用
alloc_inode从inode_cachep分配索引节点
inode_operations
对索引节点的操作,包括create、lookup、mkdir、rmdir、link、unlink等等。
文件
文件是和进程息息相关的,和文件相关的结构包括:
- file
- 文件的表示
- fs_struct
- 进程和文件系统的关系
- files_struct
- 用于将文件描述符转换为
file
file
struct file { union { struct llist_node fu_llist; struct rcu_head fu_rcuhead; } f_u; struct path f_path; #define f_dentry f_path.dentry struct inode *f_inode; const struct file_operations *f_op; atomic_long_t f_count; unsigned int f_flags; fmode_t f_mode; loff_t f_pos; struct fown_struct f_owner; u64 f_version; void *private_data; spinlock_t f_lock; struct mutex f_pos_lock; const struct cred *f_cred; struct file_ra_state f_ra; struct address_space *f_mapping; } __attribute__((aligned(4)));
相关函数:
- alloc_file
- 调用
get_empty_filp从filp_cachep分配一个文件
file_operations
这个操作集包含了对文件的所有操作,如读取、写入、打开和关闭等等。
fs_struct
主要包含两个路径,一个是当前工作目录,一个是工作目录所在文件系统的根目录。主要体现了进程和具体文件系统的关系。
struct fs_struct { int users; spinlock_t lock; seqcount_t seq; int umask; int in_exec; struct path root, pwd; }; struct path { struct vfsmount *mnt; struct dentry *dentry; };
files_struct
主要就是一个file指针数组,我们通常说的文件描述符是一个整数,而这个整数正好可以作为下标,从而从files_struct中获得file结构。具体查找是通过fdt->fd[fd]来找到对应的file。
struct files_struct { atomic_t count; struct fdtable __rcu *fdt; struct fdtable fdtab; spinlock_t file_lock ____cacheline_aligned_in_smp; int next_fd; // 当前fd + 1 unsigned long close_on_exec_init[1]; unsigned long open_fds_init[1]; struct file __rcu * fd_array[NR_OPEN_DEFAULT]; };
- fdt
默认是指向fdtab的,当打开的文件数目比较多的时候,就需要重新分配一个fdtable,并增大其fd数组和打开位图,然后将这个fdt指向新分配的fdtable。原来fdt所指向的内存会复制到新的fdtable。
至于如何判断fdt是否指向动态fdtable,也就是最后是否需要释放fdt所指向的内存,可以通过判断fdt和fdtab的地址是否相等来确定。
- file_lock
- 保护对file_struct的修改。
从文件描述符转换为file的关键数据结构就是fdtable。
struct fdtable { unsigned int max_fds; // 最大可打开文件数,即fd数组长度 struct file __rcu **fd; // fd数组 unsigned long *close_on_exec; // 位图:带O_CLOEXEC打开标志的fd unsigned long *open_fds; // 位图:已经打开的fd struct rcu_head rcu; };
- fd
如果打开的文件比较少,那么这个fd将指向files_struct的fd_array。如果打开的文件比较多,fdtable本身就是动态分配的,fd也是动态分配。所以是否要释放fd所指空间很好判断,如果要释放fdtable就一定会释放fd。对fd的分配会尝试kmalloc()和vmalloc()两种方法。
另外,close_on_exec与open_fds的行为同fd,如果fdtable是动态分配的,那么他们也必然是动态分配的。
目录项
dentry
struct dentry { unsigned int d_flags; // 表示支持哪些操作 seqcount_t d_seq; struct hlist_bl_node d_hash; struct dentry *d_parent; struct qstr d_name; // 名字及hash值, struct inode *d_inode; // 关联inode,NULL表示negative unsigned char d_iname[DNAME_INLINE_LEN]; struct lockref d_lockref; const struct dentry_operations *d_op; struct super_block *d_sb; // 指向超级块 unsigned long d_time; // used by d_revalidate void *d_fsdata; // fs-specific data struct list_head d_lru; // sb->s_dentry_lru union { struct list_head d_child; // parent的子节点,应叫d_sibling struct rcu_head d_rcu; } d_u; // 这个名字也不恰当,因为它不仅仅包含目录,还包含文件。 struct list_head d_subdirs; // 这才是真正的children struct hlist_node d_alias; // inode->i_dentry };
相关函数:
- d_alloc
- 构造函数,从
dentry_cache分配一个negative目录项 - dput
- 析够函数,当引用计数为0时调用
dentry_kill释放目录项
dentry_operations
由于dentry主要供VFS使用,所以操作集中的函数一般情况下也不需要具体文件系统去实现。这里的函数是针对dentry的操作,如d_revalidate、d_hash、d_compare、d_delete、 d_release、d_prune等等。
比较容易混淆的是d_delete和d_prune,前者只是判断是否需要delete,如果要delete就会释放dentry,否则会将dentry加入到LRU,而后者是在unhash前的最后一步动作,当然一般也不需要实现。而d_release只会在最后调用,它负责释放内存。
挂载点
struct mount { struct hlist_node mnt_hash; // mount_hashtable[i] // mount_lock struct mount *mnt_parent; struct dentry *mnt_mountpoint; // 即mnt->mnt_root。 struct vfsmount mnt; struct rcu_head mnt_rcu; #ifdef CONFIG_SMP struct mnt_pcp __percpu *mnt_pcp; #else int mnt_count; int mnt_writers; #endif struct list_head mnt_mounts; // mount->mnt_child struct list_head mnt_child; // mount->mnt_mounts struct list_head mnt_instance; // sb->s_mounts const char *mnt_devname; // device name: "/dev/dsk/hda1" struct list_head mnt_list; // mnt_namespace->list struct list_head mnt_expire; // link in fs-specific expiry list struct list_head mnt_share; // circular list of shared mounts struct list_head mnt_slave_list;// list of slave mounts struct list_head mnt_slave; // slave list entry struct mount *mnt_master; // slave is on master->mnt_slave_list struct mnt_namespace *mnt_ns; // containing namespace struct mountpoint *mnt_mp; // where is it mounted int mnt_id; // mount identifier int mnt_group_id; // peer group identifier int mnt_expiry_mark; int mnt_pinned; struct path mnt_ex_mountpoint; }; struct vfsmount { struct dentry *mnt_root; // 挂载目录项 struct super_block *mnt_sb; // 指向super_block int mnt_flags; }; struct mountpoint { struct hlist_node m_hash; // mountpoint_hashtable struct dentry *m_dentry; int m_count; };
文件名
用户空间查询路径的时候实际是传递字符串,内核也可以只保存字符串,但是考虑到内核中查询路径过程比较复杂,单用字符串比较麻烦,就将和文件名相关的信息用一个结构体filename表示,最关键的还是其名字。
struct filename { const char *name; // - 指向用户空间的文件名,如果不是从用户空间传递则指向NULL const __user char *uptr; struct audit_names *aname; // 不讨论audit相关代码 bool separate; };
- separate
- filename设计精巧之处在于将长度小于
EMBEDDED_NAME_MAX的文件名放到filename所在空间后面,这由__getname保证。当然如果文件名长度很大,就需要单独分配空间来存放文件名。这里的separate就是为了提供线索,告诉__putname如何去释放。
相关函数:
- getname
- 即
getname_flags(filename, 0, NULL) - getname_kernel
- 该函数要求文件名长度小于
EMBEDDED_NAME_MAX,这由内核代码来保证。 - putname
- 释放
filename
基本操作
从描述符获取文件
查找文件的线路图为:current -> files_struct -> fdtable -> file,具体可以参考fget函数。但是内核在查询的时候引入一些标志,这些标志存放在file指针的低位,为了方便使用引入fd来分离低位的标志,如下所示。
struct fd { struct file *file; unsigned int flags; };
static inline struct fd fdget(unsigned int fd) { return __to_fd(__fdget(fd)); } static inline struct fd __to_fd(unsigned long v) { return (struct fd){(struct file *)(v & ~3), v & 3}; }
索引节点哈希表
哈希表结构
struct hlist_head { struct hlist_node *first; }; struct hlist_node { struct hlist_node *next, **pprev; }; static __initdata unsigned long ihash_entries; static unsigned int i_hash_mask __read_mostly; static unsigned int i_hash_shift __read_mostly; static struct hlist_head *inode_hashtable __read_mostly; static __cacheline_aligned_in_smp DEFINE_SPINLOCK(inode_hash_lock);
- i_hash_mask
- 实际长度位数,即
ilog2(ihash_entries) - i_hash_shift
- 最大索引值,即
(1 << i_hash_mask) - 1
关于hash值的计算使用的是如下函数,参数hashval实际就是inode的索引号。
static unsigned long hash(struct super_block *sb, unsigned long hashval) { unsigned long tmp; tmp = (hashval * (unsigned long)sb) ^ (GOLDEN_RATIO_PRIME + hashval) / L1_CACHE_BYTES; tmp = tmp ^ ((tmp ^ GOLDEN_RATIO_PRIME) >> i_hash_shift); return tmp & i_hash_mask; }
- insert_inode_hash
- 将inode插入哈希表
- remove_inode_hash
- 将inode从哈希表删除
目录项哈希表
哈希表结构
struct hlist_bl_head { struct hlist_bl_node *first; }; struct hlist_bl_node { struct hlist_bl_node *next, **pprev; }; static __initdata unsigned long dhash_entries; static struct hlist_bl_head *dentry_hashtable __read_mostly; static unsigned int d_hash_mask __read_mostly; static unsigned int d_hash_shift __read_mostly;
- dentry_hashtable
- 在dcache_init()/dcache_init_early()时会对其初始化
- d_hash_mask
- 实际长度位数,即
ilog2(dhash_entries) - d_hash_shift
- 最大索引值,即
(1 << d_hash_mask) - 1
对hash值的计算采用的是如下函数,注意d_hash的参数hash是将路径名转换出来的一个数字,具体转换方法比较复杂,请参考full_name_hash。
static inline u32 hash_32(u32 val, unsigned int bits) { /* On some cpus multiply is faster, on others gcc will do shifts */ u32 hash = val * GOLDEN_RATIO_PRIME_32; /* High bits are more random, so use them. */ return hash >> (32 - bits); } static inline struct hlist_bl_head *d_hash(const struct dentry *parent, unsigned int hash) { hash += (unsigned long) parent / L1_CACHE_BYTES; return dentry_hashtable + hash_32(hash, d_hash_shift); }
- d_add
- 实例化dentry并加入哈希表,所谓实例化就是和具体的inode关联
- d_lookup
- 根据路径名查找目录项,在
__d_lookup基础上加了一个顺序锁校验
复杂操作
根文件系统
注册文件系统类型
注册rootfs是在init_rootfs()中完成的,主要工作就是注册rootfs_fs_type。
static struct file_system_type rootfs_fs_type = { .name = "rootfs", .mount = rootfs_mount, .kill_sb = kill_litter_super, };
一旦我们注册好这个文件系统,在初始化rootfs的时候就会调用init_ramfs_fs(),也就是说注册了rootfs会紧接着注册ramfs,而初始化ramfs只不过就是注册ramfs_fs_type。
static struct file_system_type ramfs_fs_type = { .name = "ramfs", .mount = ramfs_mount, .kill_sb = ramfs_kill_sb, .fs_flags = FS_USERNS_MOUNT, };
挂载根文件系统
一旦注册好上面两个文件系统,接下来就要开始初始化挂载树:
- init_mount_tree
- 调用
vfs_kern_mount,创建名字空间,设置进程pwd/root路径 - vfs_kern_mount
- 分配
mount,调用mount_fs来执行挂载操作,建立挂载点关系 - mount_fs
- 调用具体文件系统提供的
mount操作,这里为rootfs_mount - rootfs_mount
- 设置
super_block填充函数为ramfs_fill_super转交给mount_nodev - mount_nodec
- 调用
sget分配super_block,用ramfs_fill_super初始化, - ramfs_fill_super
- 初始化
super_block,调用ramfs_get_inode创建根节点,调用d_make_root设置根目录项 - ramfs_get_inode
- 调用
new_inode分配一个inode,然后初始化inode_operations和file_operations - d_make_root
- 调用
__d_alloc分配一个目录项,再调用d_inistantiate和根索引节点关联
创建名字空间
在init_mount_tree完成根目录挂载之后,会为系统init进程准备namespace,其目的就是将mnt和dentry信息记录在进程数据块中。
- create_mnt_ns
- 调用
alloc_mnt_ns分配挂载名字空间mnt_namespace,然后设置挂载点和名字空间关系 - alloc_mnt_ns
- 分配名字空间
文件查询
基本概念
- 路径查找就是通过路径名查找dentry。
- 查找从路径名第1个元素开始,要么是ROOT,要么是CWD。
- 然后查找其子目录,称之为路径名的下一个元素。
- 从2.5.62开始使用了新的锁模型,利用RCU来避免使用锁。
- 从2.6.38开始使用RCU实现完全的"store-free"。
- 不需要锁,不用原子操作,不用保存常用dentry到cachelines。
如果路径名地一个字符是'/'那么就从current->fs->root开始查找,不然就从current->fs->pwd查找。
除了查找路径我们还有许多事情要做,对目录的访问权限必须检查,符号链接可能导致循环引用,内核必须考虑这些情况,文件名可能是一个新的文件系统,这时必须要能检测到并跳到新的文件系统。
数据结构
在搜索的过程中需要有一个数据结构保存中间结果,这个nameidata就起着路标的作用。
struct nameidata { struct path path; // 已解析路径 struct qstr last; // 下一个等待解析的路径元素 struct path root; // 根目录 struct inode *inode; // 已解析节点:path.dentry.d_inode unsigned int flags; // 以何种方式查询 unsigned seq, m_seq; // 顺序锁 int last_type; // 下一个要解析的路径单元类型 unsigned depth; // 符号链接深度 char *saved_names[MAX_NESTED_LINKS + 1]; };
路径查找
这里先举一个简单例子来加深理解。假设我们要创建一个"/dev"目录,创建目录是由系统调用mkdir()完成的,这个系统调用我们简单来看,包括两个部分。
第一个部分创建dentry:也就是根据文件名来创建dentry,首先要找到父目录,父目录都不用找了,直接可以从current->fs中获取。然后我们需要找一下nameidata指定的目录,看看是不是已经有这个要创建的目录了。然后创建dentry,分配是由lookup_hash()来完成的。
第二个部分是调用inode->i_op->mkdir()来创建节点,因为创建节点要dentry参数,这个参数就是用第一步分配的dentry。注意这里的inode是父目录的inode。
我们以kern_path()作为起始函数进行研究。
int kern_path(const char *name, unsigned int flags, struct path *path) { struct nameidata nd; int res = do_path_lookup(AT_FDCWD, name, flags, &nd); if (!res) *path = nd.path; return res; } static int do_path_lookup(int dfd, const char *name, unsigned int flags, struct nameidata *nd) { struct filename filename = { .name = name }; return filename_lookup(dfd, &filename, flags, nd); }
- nameidata
- 用于保存查询中间信息
- filename
- 仅内核参数,无需
getname()/putname(),可直接构造 - flags
- 查询标志位,即以什么样的方式查询
- LOOKUP_FOLLOW
- 跟随符号链接
- LOOKUP_DIRECTORY
- 最后一个目录项必须是目录
- LOOKUP_AUTOMOUNT
- 当用户试图访问挂载点下面的文件时会自动挂载
- LOOKUP_PARENT
- 查找父目录
- LOOKUP_REVAL
- 不信任dcache,直接从磁盘查找
- LOOKUP_RCU
- 从最近使用的缓存查找,这是首选也是最快的方式
- LOOKUP_OPEN
- 试图打开一个文件
- LOOKUP_CREATE
- 如果不存在会试图创建一个文件
- filename_lookup
- 调用
path_lookupat,一共有三次调用机会,第一次RCU查找,第二次REF查找,第三次REVAL查找。 - path_lookupat
- 这是文件名查找核心函数,首先初始化
nameidata,这一步转交给path_init来做,然后分解文件名并逐个查找,这一步转交给link_path_walk,要注意这个函数只会走到倒数第二个元素,这是为了便于对最后一个元素特殊处理。最后一个元素的查询交给lookup_last来做。查询完毕由complete_all来做善后工作。 - path_init
- 就是用来初始化
nameidata,如果是从根目录查找,那么设置nd->path和nd->inode为根路径和节点。如果是从相对路径查找,那么nd->path就设置为当前路径,还有一种情况是从指定文件描述符位置查找,道理都是一样的 - link_path_walk
- 这是个重量级函数,从
nd所在位置开始查询名字。这个函数主要功能在循环中,每次迭代取出一个分量,设置nd之后交给walk_component处理。如遇到.直接跳过,遇到..跳回到父目录等。如果walk_component返回1表示要跟踪符号链接,又将问题抛给nested_symlink。迭代完成就查询完成。 - walk_component
- 先尝试
lookup_fast再尝试lookup_slow - nested_symlink
- 循环调用
follow_link和walk_component,如果最后一个分量还是符号连接,就继续循环。而follow_link本质上就是调用link_path_walk,这也是为什么link_path_walk不去查找最后一个分量的原因。 - lookup_fast
- 如果RCU方式则调用
__d_lookup_rcu,当然还要对查询的结果用顺序锁校验,如果不对就返回-ECHILD,这会导致退回原点用别的方式查询。如果用普通方式就调用__d_lookup。此外还需要对查询到的目录项校验,即调用d_revalidate。最后调用follow_managed。 - lookup_slow
- 调用
__lookup_hash,然后调用follow_managed。而__lookup_hash会调用lookup_dcache,如果lookup_dcache没找到就调用lookup_real。其实lookup_dcache就是调用d_lookup,然后在找不到的情况下分配一个negative目录项,以供lookup_real使用。进一步lookup_real是调用inode_operations提供的lookup函数。当然i_op->lookup也会遵循一些惯例,如找到目录项就调用d_add加入到dcache。
文件访问
打开文件
- open
- 系统调用,转调用
do_sys_open - do_sys_open
- 根据参数计算打开标志,调用
getname获取文件名,调用get_unused_fd_flags分配文件描述符,调用do_filp_open分配文件,并和inode关联。 - get_unused_fd_flags
- 调用
__alloc_fd分配文件描述符 - __alloc_fd
- 从
fdt中的位图找第一个0位,如果满足要求就返回。如果找不到就需要扩展fdt,由expand_files来扩展。 - do_filp_open
- 和
filename_lookup一样有三次机会,只不过调用path_openat - path_openat
- 调用
get_empty_filp分配文件,剩下的部分和path_lookupat很相似,调用path_init初始化,调用link_path_walk逐个元素查询,调用do_last处理最后一步打开操作。 - get_empty_filp
- 从
filp_cachep分配一个文件 - do_last
- 最后一步的操作很复杂,状态太多。主要工作是查询最后一个元素,然后调用
follow_managed,最后调用complete_all处理查询的善后。