Linux内核内存管理
Table of Contents
常用接口
虚拟地址空间由CPU决定字长决定,按3:1将低地址部分分给用户空间,少的部分留给内核。
内核将内核地址空间分为如下三个区:
- ZONE_DMA
- 可以执行DMA操作
- ZONE_NORMAL
- 即线性映射部分
- ZONE_HIGHMEM
- 非永久性映射区
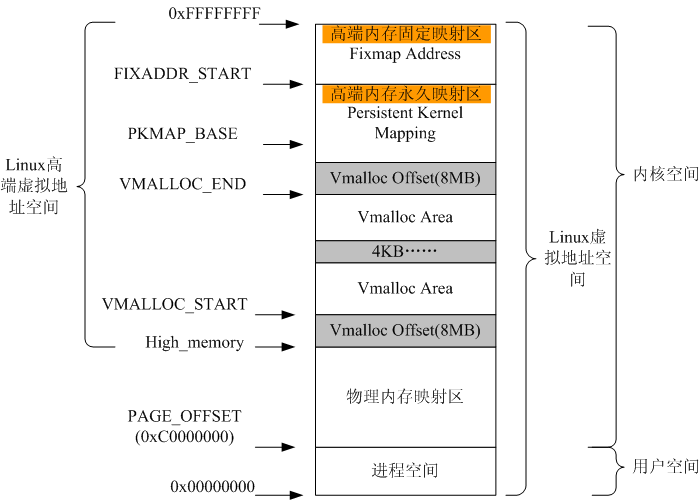
内核部分的地址和物理内存可以直接关联,也就是线性映射。如果内核分到的物理地址比地址空间大,那么多余的部分就不能通过线性映射访问,这就是所谓的高端内存。而64位CPU由于其寻址空间非常大,就没有高端内存了。高端内存只对内核空间有影响,用户空间进程总是通过页表访问内存。
获取内存
void *kmalloc(size_t size, gfp_t flags); void kfree(const void *ptr);
gfp_mask有如下一些选项:
| 标志位 | 功能 |
|---|---|
| __GFP_WAIT | 可以休眠 |
| __GFP_HIGH | 可以使用紧急内存池 |
| __GFP_IO | 可以执行IO操作 |
| __GFP_FS | 可以执行文件系统IO操作 |
| __GFP_COLD | 应该使用冷页 |
| __GFP_NOWARN | 不打印警告 |
| __GFP_REPEAT | 出错重试,重试仍可能出错 |
| __GFP_NOFAIL | 出错重试,不允许失败 |
| __GFP_NORETRY | 不重试 |
| __GFP_NOMEMALLOC | 不使用保留内存 |
| __GFP_HARDWALL | |
| __GFP_RECLAIMABLE | 标记页面为reclaimable |
| __GFP_COMP | 添加复合页属性 |
| __GFP_DMA | 只从DMA区分配 |
| __GFP_DMA32 | 只从DMA32区分配 |
| __GFP_HIGHMEM | 可以从高端内存分配 |
下表的选项是实际中经常用到的,它们其实是上表中某些选项的组合。
| GFP_ATOMIC | 不允许休眠,可在中断上下文使用 |
| GFP_NOWAIT | 直接失败,而不尝试使用紧急内存池 |
| GFP_NOIO | 不允许磁盘IO |
| GFP_NOFS | 不允许文件系统IO |
| GFP_KERNEL | 常用选项,可能休眠 |
| GFP_USER | 用于给用户空间进程分配 |
| GFP_HIGHUSER | 可以从高端内存分配,用于给用户进程分配 |
| GFP_DMA | 从DMA区分配 |
void *vmalloc(unsigned long size); void vfree(const void *addr);
vmalloc()只保证虚拟地址连续,而不保证物理地址连续,虽然大多情况下并不需要物理地址连续,但是出于性能上的考虑,内核一般不会用vmalloc,因为它需要设置页表项,并映射分散页。
在有些情况下需要频繁的分配某些结构体,为了针对这样的情况做效率上的提升,内核引入了一个slab层,用于维护一个特定对象的缓存链表,当需要该对象时,可以直接从链表去取。这样做的好处有很多,对高频操作缓存本身能提高效率,也能够减少碎片。
在逻辑层次上,一个cache就缓存一类对象,每个cache可以有多个slab,每个slab实际就是一个或多个物理页,每个slab由包含多个对象。对于小于页面的kmalloc调用,实际是基于slab提供的kmalloc函数,即在内核中除了很多专用slab分配器,还有很多是针对kmalloc提供的分配器。
struct kmem_cache *kmem_cache_create(const char *name, size_t size, size_t align, unsigned long flags, void (*ctor)(void *)); void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags); void kmem_cache_free(struct kmem_cache *cachep, void *objp); int kmem_cache_destroy(struct kmem_cache *cachep);
当然也可以直接从栈上获取内存,但是栈的大小固定为1页或2页,中断上下文有一个单独的栈,大小固定为1页。
对于高端内存,不会自动映射,所以需要手动去映射,下面的函数用于将页面映射到内核地址空间。
void *kmap(struct page *page); void kunmap(struct page *page);
直接内存访问(DMA)
DMA允许外部设备和内存直接传输数据,而不需要CPU参与,由于没有CPU,那么就需要一个DMA控制器。数据传输以两种方式触发,第一种为软件请求,以read为例:
- 进程调用read,驱动分配DMA缓冲区,指示硬件传输数据,进程睡眠
- 硬件写入DMA缓冲区,完成时触发中断
- 中断处理程序应答中断,唤醒进程
第二种为硬件请求,即硬件接收到数据要通知CPU去处理,流程如下:
- 硬件发出中断告知数据到达
- 中断处理程序分配DMA缓冲区,让设备写入到缓冲区
- 设备写完之后再次发出中断
- 中断处理程序唤醒相关进程处理接收到的数据
DMA控制器和具体的平台相关,如i386的8327有两个控制器8个通道。 DMA传输器限制在低内存,装入寄存器的地址必须是物理地址。
DMA映射的实质就是分配一段内存以便设备访问,在某些情况下,要对高端内存进行DMA操作,而高端内存又不能被外部设备访问,这个时候就要创建一个反弹缓冲区,用来作为中间体。
根据DMA缓冲区保留时间的长短,可以分为两种DMA映射。
- 一致DMA映射
- 存在于驱动的整个生命周期,可以被CPU和外围设备同时访问
- 流式DMA映射
- 为单个操作设置,通过映射CPU虚拟空间的一段地址供设备访问
一致DMA映射
static inline void *pci_alloc_consistent(struct pci_dev *hwdev, size_t size, dma_addr_t *dma_handle) { return dma_alloc_coherent(hwdev == NULL ? NULL : &hwdev->dev, size, dma_handle, GFP_ATOMIC); }
由dma_coherent_mem描述一致映射内存:
struct dma_coherent_mem { void *virt_base; u32 device_base; int size; int flags; unsigned long *bitmap; };
void *dma_alloc_coherent(struct device *dev, size_t size, dma_addr_t *dma_handle, int gfp) { void *ret; // 若是设备,得到设备的dma内存区域 struct dma_coherent_mem *mem = dev ? dev->dma_mem : NULL; int order = get_order(size); // 将size转换成order gfp &= ~(__GFP_DMA | __GFP_HIGHMEM); if (mem) { // 设备的DMA映射 int page = bitmap_find_free_region(mem->bitmap, mem->size, order); if (page >= 0) { *dma_handle = mem->device_base + (page << PAGE_SHIFT); ret = mem->virt_base + (page << PAGE_SHIFT); memset(ret, 0, size); return ret; } if (mem->flags & DMA_MEMORY_EXCLUSIVE) return NULL; } // 不是设备的DMA映射 if (dev == NULL || (dev->coherent_dma_mask < 0xffffffff)) gfp |= GFP_DMA; // 分配空闲页 ret = (void *)__get_free_pages(gfp, order); if (ret != NULL) { memset(ret, 0, size); *dma_handle = virt_to_phys(ret); } return ret; }
流式映射
static inline dma_addr_t pci_map_single(struct pci_dev *hwdev, void *ptr, size_t size, int direction) { return dma_map_single(hwdev == NULL ? NULL : &hwdev->dev, ptr, size, (enum ma_data_direction) direction); }
static inline dma_addr_t dma_map_single(struct device *dev, void *ptr, size_t size, enum dma_data_direction direction) { BUG_ON(direction == DMA_NONE); // 可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新 flush_write_buffers(); return virt_to_phys(ptr); // 虚拟地址转化为物理地址 }
分散聚集映射
struct scatterlist { struct page *page; unsigned int offset; dma_addr_t dma_address; // 用在分散聚集操作中的缓冲区地址 unsigned int length; // 该缓冲区的长度 };
static inline int pci_map_sg(struct pci_dev *hwdev, struct scatterlist *sg, int nents, int direction) { return dma_map_sg(hwdev == NULL ? NULL : &hwdev->dev, sg, nents, (enum dma_data_direction)direction); }
static inline int dma_map_sg(struct device *dev, struct scatterlist *sg, int nents, enum dma_data_direction direction) { int i; BUG_ON(direction == DMA_NONE); for (i = 0; i < nents; i++ ) { BUG_ON(!sg[i].page); // 将页及页偏移地址转化为物理地址 sg[i].dma_address = page_to_phys(sg[i].page) + sg[i].offset; } // 可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新 flush_write_buffers(); return nents; }
DMA池
有些驱动要用到许多很小的一致DMA映射,这种情况用DMA池更好。
struct dma_pool { struct list_head page_list; spinlock_t lock; size_t blocks_per_page; // 每页的块数 size_t size; // DMA池里的一致内存块的大小 struct device *dev; // 将做DMA的设备 size_t allocation; // 分配的没有跨越边界的块数 // 是size的整数倍 char name [32]; // 池的名字 wait_queue_head_t waitq; // 等待队列 struct list_head pools; };
struct dma_pool *dma_pool_create (const char *name, struct device *dev, size_t size, size_t align, size_t allocation)
内存管理
进程地址空间
内核不仅要管理自己的内存,还需要管理用户空间进程的内存,这部分内存称之为进程地址空间。 Linux本身是一个虚拟化内存管理系统,也就是说每个进程从自己的视觉来看,就像是独占整个系统的内存资源一样。并且可以麻痹进程,让进程可以看到比物理内存大的内存。大体上虚拟内存管理技术有如下优点:
- 进程不能直接访问物理地址,安全性更好,并可以看到比物理地址更广的空间
- 多个相同程序同时运行时,可以看到同样的虚拟地址
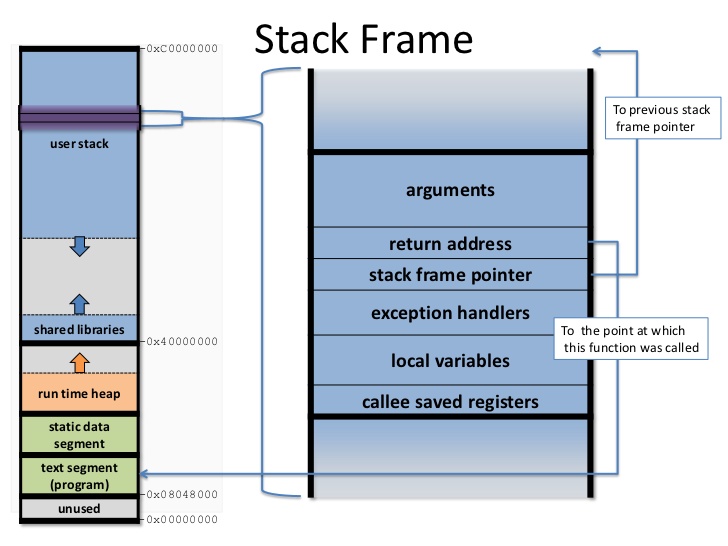
进程地址空间作为一个平坦模型展示,意味着进程在32位机上可以访问0-4GB空间,有些操作系统提供分段地址空间,也就是由多个段组成。不过现代操作系统都用平坦模型。虽然进程地址空间范围是0-4GB,但是有些地方是不允许访问的。允许访问的区间为0x08048000-0xc0000000,被称之为内存区。当进程试图访问不允许访问的内存时,内核就会杀死进程,用户就能看到经典提示Segmentation Fault。内存区分为如下几个部分:
- text
- 可执行文件代码,一般就叫做代码段,只读区
- data
- 已初始化全局变量,包括静态变量,保存在可执行文件中
- bss
- 全称block started by symbol,全0页,未初始化全局变量,注意text和data段在可执行文件中,而bss不在,由系统初始化
- stack
- 存放程序临时创建的局部变量,全0页,参数和返回值都会压入栈中
- heap
- 用于动态分配的内存段
- additon
- 额外的text、data、bss段,用于共享库
- files
- 内存映射的文件
- shared
- 共享内存段
- anonymous
- 匿名内存映射,例如关联malloc
这里说明一下bss段存在的意义,实际上最简单的做法是把bss段直接当作data段处理,但是为了进一步优化可执行文件的大小,才引入bss段。既然bss段都会清0,那么就没有必要保存起来,当程序启动时由系统将其初始化即可。静态变量也是一样的道理,已初始化就放到data段,未初始化就放到bss段。
下面的示例程序用来打印各段地址:
#include<stdio.h> #include<malloc.h> #include<unistd.h> int bss_var; int data_var0=1; int main(int argc, char **argv) { printf("Text: main address: %p\n", main); int stack_var0=2; printf("Stack: stack end 0: %p\n", &stack_var0); int stack_var1=3; printf(" stack end 1: %p\n", &stack_var1); printf("Data: Data 0: %p\n", &data_var0); static int data_var1=4; printf(" Data 1: %p\n", &data_var1); printf("BSS: bss_var: %p\n", &bss_var); char *b = (char *)sbrk((ptrdiff_t)0); printf("Heap: heap 0: %p\n", b); brk(b+4); b = (char *)sbrk((ptrdiff_t)0); printf(" heap 1: %p\n", b); return 0; }
Text: main address: 0x4005bd
Stack: stack end 0: 0x7fffb82edae0
stack end 1: 0x7fffb82edae4
Data: Data 0: 0x601050
Data 1: 0x601054
BSS: bss_var: 0x60105c
Heap: heap 0: 0x15d4000
heap 1: 0x15d4004
内核用内存描述符来表示进程地址空间,即mm_struct结构。
- mmap/mm_rb
- 前者是一个单向链表,后者是一个二叉树,两个数据结构都是用来描述所有内存的,只不过一个擅长遍历,一个擅长查询
- mmlist
- 通过该节点将所有
mm_struct接入到全局链表init_mm,全局链表受mmlist_lock保护
进程可以通过在clone()是传递选项CLONE_VM来共享内存,这样就导致新产生的是线程而不是进程,这就是线程和进程的唯一区别。内核线程是不需要的进程地址空间的,因此不需要关联内存描述符,之所以不要,是因为内核线程不需要访问用户空间存储。
内核中用vm_area_struct来表示内存区,内存区通常被称为虚拟内存区VMA。每个vm_erea_struct描述一个特定的内存区,如内存映射文件、进程栈等。一个vm_erea_struct所表示的内存范围由(vm_start, vm_end]来描述。如果两个线程共享地址空间,那么两个线程共享所有的vm_erea_struct。前面提到mmap/mm_rb是用来描述所有内存的,它们的节点就是vm_erea_struct。一个进程的内存区可以通过文件/proc/pid/maps查看。文件格式为:
start-end perm offset major:minor inode file 00400000-0041f000 r-xp 00000000 00:11 25870 /usr/lib/... 0061e000-0061f000 r--p 0001e000 00:11 25870 /usr/lib/... 0061f000-00620000 rw-p 0001f000 00:11 25870 /usr/lib/... 01b37000-01ecc000 rw-p 00000000 00:00 0 [heap]
另外也可以通过程序pmap来查看一个进程的内存空间信息。
pmap [options] pid [...]
页表管理
虽然用户进程只会操作虚拟地址,但是处理器实际上是操作物理地址。所以处理器真正操作物理地址之前都需要一道转换程序,这种转换是通过查询页表来完成的。页表的功能就是完成对虚拟地址到物理地址的转换。 Linux采用三级页表进行转换,分别是PGD、PMD、PTE,即全局目录,中间目录,目录项。在大多数机器上,页表查询都是由硬件来完成的。每个进程有自己独立的页表,线程共享。为了能够加速查询过程,处理器实现了TLB,Translation Lookaside Buffer,就是一个cache。
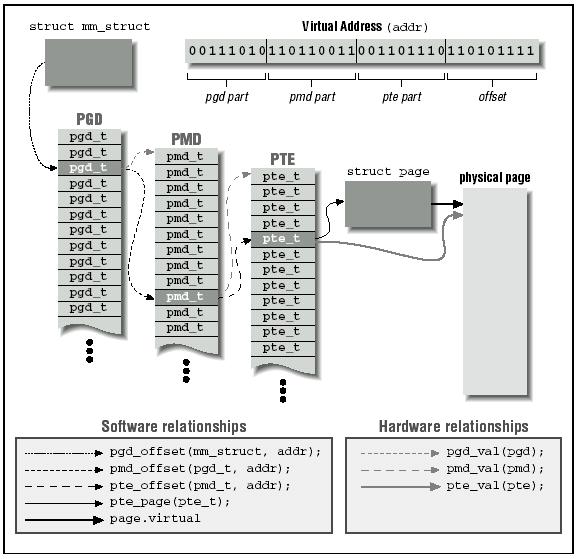
页表其本质就是页框的数组,只不过用一维数组不够用,要用多维来节省存储空间。而具体的每个页表项就是一个无符号长整型,高位31-12表示页框地址,低位表示属性。为什么低12位可以留作它用呢?因为每个页框的大小是4KB。
Linux物理内存管理通过分页机制实现,分页可以让系统将页面拼凑出程序需要的大块内存,而不必连续页面。当然连续页面的好处是能降低TLB刷新率,为了降低刷新率,内核采用伙伴算法来管理空闲页面。这也是为什么get_free_pages只能获取2的幂的数量。用户空间调用malloc分配内存实际是通过brk来扩大或缩小进程堆空间,当现有空间不足时,内核会以页面为单位进行扩张。物理页面由page表示。
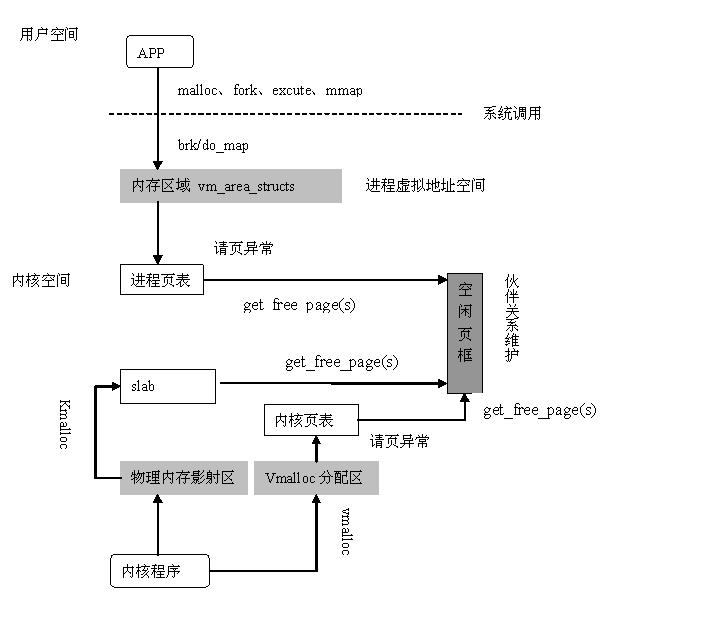
地址转换过程分为如下几个步骤:
- 从CR3寄存器读取PGD所在基地址,从虚拟地址(也叫线性地址)第一部分获取页目录项索引,相加得到页目录项物理地址。
- 读取PGD项,从中取出PUD基地址
- 从虚拟地址第二部分获取PUD索引,和PUD基地址相加得PUD物理地址
- 读取PUD项,从中取出PMD基地址
- 从虚拟地址第三部分获取PMD索引,和PMD基地址相加得PMD物理地址
- 读取PMD项,从中取出PTE基地址
- 从虚拟地址第四部分获取PTE索引,和PTE基地址相加得PTE物理地址
- 读取PTE项,从中取出物理页基地址
- 从虚拟地址第五部分获取页内偏移,和物理页基地址相加得到最终物理地址
- 最后可以从物理地址得到需要的数据
内存管理
Linux内核将物理页作为基本管理单元,32位机上一页为4KB,
64位机上一页为8KB。内核中用page来描述物理页。由于每个物理页都需要一个page来描述,所以该结构体必须十分紧凑,另外要注意它只是描述物理页,而不是物理页中的数据。
- count
- 当有人使用该页面的时候,计数器就不为0,使用者可以是page cache, private数据或进程页表。
- virtual
- 用于指向页面的虚拟地址,对于高端内存来说,如果没有做映射,该字段就指向NULL
内存碎片
内存碎片分为两种,一种叫内部碎片,一种叫外部碎片。内部和外部其实是相对于进程来说的,进程在请求内存时,系统在很多时候都不是精确分配,往往会多分配一点,这通常是出于性能和边界等考虑,那么多处的部分就是内部碎片。而外部碎片是因为系统在分配存储时,由于某些原因留下很多较小的空闲段,这些段因为太小,不能满足分配请求,就会形成外部碎片。
简单的说,固定分区存在内部碎片,可变式分区存在外部碎片,页式虚拟存储存在内部碎片,段式虚拟存储存在外部碎片。例如最后一页装不满就形成内部碎片,而5K的段换出后,再换进4K的段,剩下的1K就是外部碎片。
连续分配方式
出现在早期,具体还可以分为:单一连续分配、固定分区分配、动态分区分配、动态重定位分区分配。
分页管理
连续分配会出现很多碎片,分页管理是一个进程占用多个不连续的页,系统为每个进程建立一张页面映射表,简称页表,页表的作用是实现从页号到物理块号的映射。页面管理方式会在进程最后一页形成内部碎片。
分段管理
分段和分页思路上是完全一样的,只不过页面大小是固定的,而段的长度不是固定的。所以分段管理存在外部碎片。
段页式管理
分页可以更好的管理内存,分段可以更好的满足用户需求,结合起来将用户程序分成若干段,每个段分若干页,地址结构包括段号、段内页号和页内偏移三部分。
页缓存
页缓存page cache本质上应该叫disk cache,因为缓存的目的起始是为了减少磁盘IO。用户在向磁盘写入数据的时候,实际上是写入到内存中,内核定期将内存中的数据更新到磁盘,称之为回写page writeback。同样,当用户要读取数据的时候,可以直接从内存得到需要的数据。
在内存不够用的时候就需要回收部分缓存,LRU是一种基本的回收机制,将最后访问的文件插入到LRU链表,当内存不够用的时候就释放LRU中很久没有访问的文件。这样的方法其实还是有缺陷的,因为有些文件用一次就不用了,有些文件会频繁使用。 Linux使用的LRU变体,即双链表策略,一个活动链表,一个不活动链表,当一个不活动链表中的文件被访问时,它就被加入到活动链表。当活动链表太长的时候,其尾部节点就扔到不活动链表,这种方法记位LRU/2。
一个页缓存中的页可以是物理上不连续的磁盘块,Linux对page cache的设计下了大功夫,只要是基于页面的对象都可以缓存,包括文件、内存映射等等。
Linux用address_space来描述缓存页,一个文件可以有多个vm_area_struct但是只有一个address_space,因为一个文件可以有多个虚拟地址,但是只有一个物理内存。
内核在做IO操作之前必须检查是否有缓存页,所以要能具有快速搜索能力,在每个address_space中都有一个radix tree,内核利用该数据结构来进行页面查找。在早期内核是通过哈希表查找的,使用全局哈希表有如下一些问题:
- 访问全局变量需要锁,高频率的获取锁是有效率问题的
- 一个巨大的哈希表是没有必要的,因为我们只需要查找和文件关联的页
- 当页面不存在的时候效率很低,因为你需要遍历冲突链表才知道不存在
- 全局哈希很占空间
除了这里提到的页缓存,对于块设备来说,还有一个块缓存,在通用块层提供了从内存块到物理块的映射。也就是对块的IO操作必须以单个磁盘块为单位,内核通过bread()来从磁盘读取一个块。
为了能够将缓存页回写到磁盘上,内核提供了一个刷新线程。在如下几种情况下去执行回写操作:
- 内存紧张,需要释放部分缓存
- 脏数据缓存时间到期
- 用户调用sync或fsync
此外Linux还支持一种称为laptop的模式,将/proc/sys/vm/laptop_mode设置为1可以打开。该模式能够省电,其工作原理是当一个文件缓存时间到期后,刷新所有到期文件。当然必须要配置到期时间足够长,如10分钟,这样的后果就是一旦崩溃,系统可能就挂了。
进阶概念
vmalloc
vmalloc在地址空间范围由VMALLOC_START和VMALLOC_END限定,内部又分为多个vmalloc区,间隔为4KB,由vm_struct描述每个区,所有的vm_struct组成一个全局链表vmlist。
struct vm_struct { struct vm_struct *next; // 链表下一节点 void *addr; // 内存区起始地址 unsigned long size; // 区域大小 unsigned long flags; // 内存区类型 struct page **pages; // 每个page关联到一个物理页帧 unsigned int nr_pages; // 总page数 phys_addr_t phys_addr; // 通常为0,用于ioremap const void *caller; // 返回地址 };
void *vmalloc(unsigned long size) { return __vmalloc_node_flags(size, NUMA_NO_NODE, GFP_KERNEL | __GFP_HIGHMEM); } static inline void *__vmalloc_node_flags(unsigned long size, int node, gfp_t flags) { return __vmalloc_node(size, 1, flags, PAGE_KERNEL, node, __builtin_return_address(0)); } static void *__vmalloc_node(unsigned long size, unsigned long align, gfp_t gfp_mask, pgprot_t prot, int node, const void *caller) { return __vmalloc_node_range(size, align, VMALLOC_START, VMALLOC_END, gfp_mask, prot, 0, node, caller); } void *__vmalloc_node_range(unsigned long size, unsigned long align, unsigned long start, unsigned long end, gfp_t gfp_mask, pgprot_t prot, unsigned long vm_flags, int node, const void *caller);
- size
- 要分配的大小
- align
- 1表示将size大小的虚拟内存作为一个整体
- start-end
- 指定VMALLOC区范围
- gfp_mask
- 高端内存:
GFP_KERNEL | __GFP_HIGHMEM - prot
- 保护标志,即内核权限:PAGE_KERNEL
- vm_flags
- 0
- node
- 用于分配的节点,或者
NUMA_NO_NODE表示未指定节点 - caller
- 返回地址
具体的分配流程如下:
__get_vm_area_node查找空闲内存,由(start, end)指定范围__vmalloc_area_node分配物理页框
malloc
从进程地址空间可以看到,break将堆分成两半,下面是已经映射的堆,上面是未映射的堆。提供了两个接口修改break的位置:
int brk(void *addr); // return 0 for ok void *sbrk(intptr_t increment); // return (void *)-1 when failed
实际malloc的实现中除了用到brk还会用到mmap, mmap用到堆和栈中间的一块虚拟内存,也叫文件映射区。 malloc小于128KB的时候就调用brk,将break往高处推,当首次读写的时候发生缺页中断才会分配实际物理页,并建立映射关系。 malloc大于128KB的时候是由mmap分配,所以会初始化为0。用brk分配的主要问题是高地址释放之后低地址才能释放,虽然释放低地址不会释放物理地址,但是好在malloc可以重用。当高地址空闲长度大于128KB时即可发生紧缩,降低break位置。
mmap
内存映射mmap可以将内存映射到文件上,可以访问文件来达到访问内存的目的,同样可以通过对内存读写来达到对设备内存的读写。用户调用mmap时,最终会调用到file_operations提供的mmap。建立页表可以调用remap_page_range一次建立所有映射区页表,也可以用vma_struct的nopage在缺页时现场建立。