Linux内核数据结构
Table of Contents
Linux基本数据结构
在Linux内核中经常用到的数据结构有链表、队列、映射和二叉树。这里介绍的链表包括双向链表和哈希链表,队列是内核提供kfifo。映射是idr,所谓idr就是根据整数查询指针。
链表
双向链表
#include <linux/list.h> struct list_head { struct list_head *next, *prev; };
双向链表的结构只有两个指针,那么如何保存数据呢,和其他嵌入式数据结构一样,双向链表嵌入到其他数据结构中,可以根据二者在内存中的位置关系利用链表地址反向计算数据地址。计算的函数如下。
#define list_entry(ptr, type, member) container_of(ptr, type, member) #define container_of(ptr, type, member) \ (type *)((char *)(ptr) - (char *) &((type *)0)->member)
根据提供的链表指针ptr,包含的数据类型type,以及链表在type的成员名字member,就可以反向计算出type的地址。
生命周期
// 将链表初始化,也就是prev和next都指向自身 #define LIST_HEAD_INIT(name) { &(name), &(name) } #define LIST_HEAD(name) \ // 静态定义一个双向链表 struct list_head name = LIST_HEAD_INIT(name) // 和LIST_HEAD_INIT功能一样,这里传递的是指针,而前面传递的是对象 void INIT_LIST_HEAD(struct list_head *list);
基本操作
读者不妨思考一下下面这些函数为什么这么定义,以及如何实现这些函数。
// 为了简便,entry和head均表示struct list_head * void list_add(entry, head); // add entry after head void list_add_tail(entry, head); // add entry before head void list_del(entry); // delete entry void list_del_init(entry); // delete and init entry void list_replace(old_entry, new_entry); void list_replace_init(old_entry, new_entry); // init old_entry void list_move(entry, head); // move entry after head void list_move_tail(entry, head); // move entry before head bool list_empty(head); // check if empty by next int list_empty_careful(head); // check if empty by next & prev int list_is_last(entry, head); // check if last entry int list_is_singular(head); // check if only on entry void list_rotate_left(head); // move first to last
高级操作
// 为了简便,entry和head均表示struct list_head * void list_cut_position(list, head, entry); // list = [head, entry] // head = [entry->next, tail] void list_splice(list, head); // insert list after head // list self is head, so not insert void list_splice_tail(list, head); // insert list before head void list_splice_init(list, head); // insert after head, init list void list_splice_tail_init(list, head); // insert before head, init list
链表遍历
在使用双向链表的时候要遵循一个规则,那就是链表头不能嵌入到数据中,也就是说链表头和普通的链表节点是不一样的。所以不能对链表头调用list_entry(),而必须使用下面的宏。
#define list_first_entry(ptr, type, member) \ list_entry((ptr)->next, type, member) #define list_last_entry(ptr, type, member) \ list_entry((ptr)->prev, type, member)
另外比较常用的操作是迭代链表,主要可以用如下一些宏。
#define __container_of(ptr, sample, member) \ (void *)container_of((ptr), typeof(*(sample)), member)
这个宏的特殊之处在于我们不是去指定链表保存的数据类型,而是直接传递数据指针,由typeof去帮我们提取数据类型。
#define list_for_each_entry(pos, head, member) \ for (pos = __container_of((head)->next, pos, member); \ &pos->member != (head); \ pos = __container_of(pos->member.next, pos, member)) #define list_for_each_entry_safe(pos, tmp, head, member);
pos是我们想要得到的数据指针,head是链表头,所以必须从next开始获取,结束条件是我们拿到了head的数据,显然这个数据是无效的。一旦我们有了pos,往后面迭代的时候就不需要使用head,而直接可以使用pos->member了。当然,如果我们在迭代过程中将当前节点删除,还不会有什么问题,但是一旦我们删除后有对当前节点初始化,那么迭代就会终止。更可怕的是如果我们将当前节点移动到了别的地方,那么就会产生致命错误,极可能系统崩溃。安全版本可以删除当前元素,因为已经用tmp记录了下一个元素的位置。
此外还可以进行反向迭代。
#define list_for_each_entry_reverse(pos, head, member); #define list_for_each_entry_safe_reverse(pos, tmp, head, member);
哈希链表
哈希链表本质上还是双向链表,当next为NULL的时候就是链表尾部,但是又可以通过pprev来改变前一个节点。
#include <linux/list.h> struct hlist_head { struct hlist_node *first; }; struct hlist_node { struct hlist_node *next, **pprev; };
哈希表的本质是hlist_head的一个数组,既然是数组,长度就是固定的。每当要向表中一个位置添加节点时,就将hlist_node加入到hlist_head所指定的链表中。这里和双向链表的设计思路完全一样,链表头不用来存放数据,仅仅作为重要的参照标志。为了节省空间,链表头只包含一个指针。
这里出现了一个pprev指针,它指向上一个hlist_node的next指针的地址,如果前一个节点是hlist_head,那么就是hlist_head的first的地址。之所以要用这么一个指针,而不是是像链表一样直接用prev,是存在技术上的困难,因为prev可能是hlist_head也可以是hlist_node,但是如果将其含义修改为上一节点的next指针地址,就可以用统一的hlist_node二级指针表示。
生命周期
#define HLIST_HEAD(name) struct hlist_head name = { .first = NULL } #define HLIST_HEAD_INIT { .first = NULL } #define INIT_HLIST_HEAD(ptr) ((ptr)->first = NULL) static inline void INIT_HLIST_NODE(struct hlist_node *h) { h->next = NULL; h->pprev = NULL; }
基本操作
// 为了简便,node表示struct hlist_node *,head表示struct hlist_head * #define hlist_entry(ptr, type, member); // ref list_entry() int hlist_unhashed(node); // check if inserted hash table int hlist_empty(head); // check if empty void hlist_del(node); // delete node void hlist_del_init(node); // delete and init node void hlist_add_head(node, head); // insert to head->first void hlist_add_before(node, pos); // insert node before pos void hlist_add_behind(node, pos); // insert node behind pos void hlist_move_list(head, new_head); // move list to new_head // head->first will be NULL
哈希链表的遍历和双向链表工作原理一样,不过实现上要复杂一点,并且没有反向迭代的版本。
#define hlist_for_each_entry(pos, head, member); #define hlist_for_each_entry_safe(pos, tmp, head, member);
队列 - kfifo
FIFO就是先进先出的意思,一般用队列表示,Linux Kernel实现了一个通用的FIFO,称之为KFIFO。
本文参照linux-kernel-3.19,由于代码相对于老的接口有一些变动,所以对于用户来说需要作出如下一些更变。
- 将类型声明由
struct kfifo *变为struct kfifo - 使用
kfifo_alloc()或kfifo_init()初始化 kfifo_in/kfifo_out替代__kfifo_put/__kfifo_get表示免锁算法kfifo_in_spinlocked/kfifo_out_spinlocked替代kfifo_put/kfifo_get表示要加锁的算法__kfifo_*函数被更名为kfifo_*
如果只有一个写入者,一个读取者,是不需要锁的。对于多个写入者,一个读取者,只需要对写入者上锁。反之,如果有多个读取者,一个写入者,只需要对读取者上锁。
另外在实现上用到了比较特殊的技巧,内核实现了两类KFIFO,一种就是struct kfifo,也就是动态KFIFO,data段动态分配,这里称之为动态KFIFO。一种是匿名KFIFO,buf段长度不为0,data段指向buf,静态分配,这里称之为静态KFIFO。这也是为什么几乎所有的方法都用宏定义,这样可以避免类型检查。
基本用法
一般用法是在结构体中嵌入一个kfifo结构,可以是静态KFIFO也可以是动态KFIFO。
// all fifo is a pointer int kfifo_alloc(fifo, unsigned int size, gfp_t gfp_mask); void kfifo_free(fifo); unsigned int kfifo_size(fifo); // mask + 1 unsigned int kfifo_len(fifo); // in - out int kfifo_is_empty(fifo); // in == out int kfifo_is_full(fifo); // len > mask unsigned int kfifo_avail(fifo); unsigned int kfifo_reset(fifo); // in = out = 0 void kfifo_reset_out(fifo); // out = in unsigned int kfifo_unused(fifo); // len - (in - out) unsigned int kfifo_in(fifo, void *buf, unsigned int num); unsigned int kfifo_out(fifo, void *buf, unsigned int num);
源码分析
数据结构
#include <linux/kfifo.h> struct __kfifo { unsigned int in; // point to head unsigned int out; // point to tail unsigned int mask; // FIFO total size unsigned int esize; // element size void *data; // data buffer };
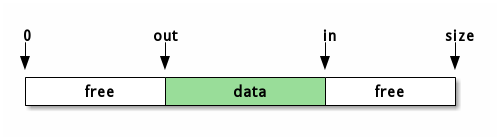
环形队列如下图所示,读取者将out向右推,写入者将in向右推。
但是到目前为止,还没有看到struct kfifo的定义,实际上它是由一组宏来定义的。
#define __STRUCT_KFIFO_COMMON(datatype, recsize, ptrtype) \ union { \ struct __kfifo kfifo; \ datatype *type; \ const datatype *const_type; \ char (*rectype)[recsize]; \ ptrtype *ptr; \ ptrtype const *ptr_const; \ } #define __STRUCT_KFIFO_PTR(type, recsize, ptrtype) \ { \ __STRUCT_KFIFO_COMMON(type, recsize, ptrtype); \ type buf[0]; \ } struct kfifo __STRUCT_KFIFO_PTR(unsigned char, 0, void);
- type
- 实际就是队列元素的类型,kfifo以unsigned char作为元素类型
- recsize
- 全称叫record size,很显然kfifo的record size为0. 因此下文不再讨论recsize不为0的情况。
这段代码设计非常精巧,我们知道kfifo中并不包含元素数据类型,元素指针类型,那么如何利用kfifo来确定相关数据类型呢?共同体为我们保存了这些信息,例如我们要想知道fifo的元素类型,就可以通过typeof(*fifo->type)获取。也就是除了buf是直接用于存储数据以外,其它的字段是为了获取类型。也就是说共同体内部处理fifo之外,我们并不会去关注其它变量,即便用其它变量也不过是利用它们获取类型,而绝不会使用它们的值。
另外有个宏用于判断指针是否为kfifo。
#define __is_kfifo_ptr(fifo) (sizeof(*fifo) == sizeof(struct __kfifo))
这个宏在很多地方都有用到,这也是设计者考虑问题比较复杂所致,如果是kfifo,就意味着fifo->buf数组长度为0,data部分单独分配。如果是其它fifo,fifo->buf长度不为0,data就会指向这部分。这里说其它fifo是指匿名结构体,它和kfifo唯一不同之处是buf的长度不为0。
静态定义
kfifo的实现中运用了大量的宏,并且比较复杂,因此先找一个比较简单的切入口,逐步分析。 DECLARE_KFIFO用于静态声明一个kfifo对象。
#define __STRUCT_KFIFO(type, size, recsize, ptrtype) \ { \ __STRUCT_KFIFO_COMMON(type, recsize, ptrtype); \ type buf[((size < 2) || (size & (size - 1))) ? -1 : size]; \ } #define STRUCT_KFIFO(type, size) \ struct __STRUCT_KFIFO(type, size, 0, type) #define DECLARE_KFIFO(fifo, type, size) STRUCT_KFIFO(type, size) fifo
- fifo
- 要定义的kfifo的名字
- type
- 元素的类型
- size
- kfifo可容纳的元素个数,必须是2的幂
- buf
- 用于存放元素,
size & (size - 1)用于检测大小是否为2的幂
如果你仔细看就会发现DECLARE_KFIFO是一个匿名结构体,它和kfifo不是一回事!这也是为什么很多地方都要用到__is_kfifo_ptr的原因。
DECLARE_KFIFO只是声明一个变量,初始化用如下宏,注意看下面就应该知道,之所以用typeof而不是直接用struct kfifo *就是因为两者不是一回事。
#define INIT_KFIFO(fifo) \ (void)({ \ typeof(&(fifo)) __tmp = &(fifo); \ struct __kfifo *__kfifo = &__tmp->kfifo; \ __kfifo->in = 0; \ __kfifo->out = 0; \ __kfifo->mask = __is_kfifo_ptr(__tmp) ? 0 : \ ARRAY_SIZE(__tmp->buf) - 1; \ __kfifo->esize = sizeof(*__tmp->buf); \ __kfifo->data = __is_kfifo_ptr(__tmp) ? NULL : __tmp->buf; \ })
动态分配
静态分配的情况其实比较少见,更多的是动态的分配。
1: #define kfifo_alloc(fifo, size, gfp_mask) \ 2: __kfifo_int_must_check_helper(({ \ 3: typeof((fifo) + 1) __tmp = (fifo); \ 4: struct __kfifo *__kfifo = &__tmp->kfifo; \ 5: __is_kfifo_ptr(__tmp) ? \ 6: __kfifo_alloc(__kfifo, size, sizeof(*__tmp->type), gfp_mask) : \ 7: -EINVAL; \ 8: }))
- 4
typeof((fifo) + 1)这里为什么要加1呢,主要的好处是帮助确定传递的参数类型是否正确,如果传递的是结构体会产生编译错误。如果传递的是数组名,如int fifo[4],typeof(fifo)的结果为int [4],而使用typeof(fifo + 1)结果为int *。所以可以认为主要是为了转换数组类型为指针类型。- 6
- 给fifo->data分配空间
入队
static void kfifo_copy_in(struct __kfifo *fifo, const void *src, unsigned int len, unsigned int off) { unsigned int size = fifo->mask + 1; unsigned int esize = fifo->esize; unsigned int l; off &= fifo->mask; if (esize != 1) { off *= esize; size *= esize; len *= esize; } l = min(len, size - off); memcpy(fifo->data + off, src, l); memcpy(fifo->data, src + l, len - l); smp_wmb(); // update data before increase fifo->in } unsigned int __kfifo_in(struct __kfifo *fifo, const void *buf, unsigned int len) { unsigned int l; l = kfifo_unused(fifo); if (len > l) len = l; kfifo_copy_in(fifo, buf, len, fifo->in); fifo->in += len; return len; } #define kfifo_in(fifo, buf, n) \ ({ \ typeof((fifo) + 1) __tmp = (fifo); \ typeof(__tmp->ptr_const) __buf = (buf); \ unsigned long __n = (n); \ struct __kfifo *__kfifo = &__tmp->kfifo; \ __kfifo_in(__kfifo, __buf, __n); \ }) #define kfifo_in_spinlocked(fifo, buf, n, lock) \ ({ \ unsigned long __flags; \ unsigned int __ret; \ spin_lock_irqsave(lock, __flags); \ __ret = kfifo_in(fifo, buf, n); \ spin_unlock_irqrestore(lock, __flags); \ __ret; \ })
出队
static void kfifo_copy_out(struct __kfifo *fifo, void *dst, unsigned int len, unsigned int off) { unsigned int size = fifo->mask + 1; unsigned int esize = fifo->esize; unsigned int l; off &= fifo->mask; if (esize != 1) { off *= esize; size *= esize; len *= esize; } l = min(len, size - off); memcpy(dst, fifo->data + off, l); memcpy(dst + l, fifo->data, len - l); smp_wmb(); // copy data before increase fifo->out } unsigned int __kfifo_out_peek(struct __kfifo *fifo, void *buf, unsigned int len) { unsigned int l; l = fifo->in - fifo->out; if (len > l) len = l; kfifo_copy_out(fifo, buf, len, fifo->out); return len; } unsigned int __kfifo_out(struct __kfifo *fifo, void *buf, unsigned int len) { len = __kfifo_out_peek(fifo, buf, len); fifo->out += len; return len; } #define kfifo_out(fifo, buf, n) \ __kfifo_uint_must_check_helper(({ \ typeof((fifo) + 1) __tmp = (fifo); \ typeof(__tmp->ptr) __buf = (buf); \ unsigned long __n = (n); \ struct __kfifo *__kfifo = &__tmp->kfifo; \ __kfifo_out(__kfifo, __buf, __n); \ })) #define kfifo_out_spinlocked(fifo, buf, n, lock) \ __kfifo_uint_must_check_helper(({ \ unsigned long __flags; \ unsigned int __ret; \ spin_lock_irqsave(lock, __flags); \ __ret = kfifo_out(fifo, buf, n); \ spin_unlock_irqrestore(lock, __flags); \ __ret; \ }))
映射 - idr
在Linux中,IDR是一个Small id to pointer translation service,用于管理整数ID,将整数和指针映射。使用的时候首先为一个数据结构的指针分配一个整数ID,接下来通过ID可以快速查找对应的指针。
数组和链表也能用于这样的转换,但是数组不能用于查询范围很大的情况,链表的迭代效率很低,因此不能用于映射量很大的情况。某些情况下可以用hash表来替代IDR,但是IDR相比于hash表来说不必预分配一个很大的数组,并且最坏情况要比hash表好。平衡二叉树能更好的控制最坏情况,但是IDR处理的情况比较特殊,只需要管理整数和指针,所以可以实现出比平衡二叉树更优的算法,不论在存储上还是在查询上都表现更好。 IDR也是一种radix tree,每个节点有256个分支,通过一些技巧性的位运算可以得到很高的查询效率。
基本用法
创建与销毁
静态初始化接口如下所示。
#define IDR_INIT(name) {.lock = __SPIN_LOCK_UNLOCKED(name.lock),} #define DEFINE_IDR(name) struct idr name = IDR_INIT(name)
动态初始化接口如下所示。
void idr_init(struct idr *idp) { memset(idp, 0, sizeof(struct idr)); spin_lock_init(&idp->lock); }
释放接口如下:
void idr_remove(struct idr *idp, int id); void idr_destroy(struct idr *idp);
- idr_remove
- 删除id并释放相关数据。
- idr_destroy
- 释放所有的id映射和层。
分配ID
void idr_preload(gfp_t gfp_mask); int idr_alloc(struct idr *idp, void *ptr, int start, int end, gfp_t gfp_mask); void idr_preload_end(void);
- idr_preload
- 调用idr_alloc之前需要调用idr_preload,用于载入percpu层缓冲,并且只能在进程上下文使用。当然idr_preload还做了一件重要的事情就是禁止抢占。
- idr_alloc
- 用于分配一个ID和指针关联,分配的值区间为[start, end)。当我们指定end的数值小于等于0的时候,默认就视为INT_MAX。
- idr_preload_end
- 启用内核抢占。
基本上使用IDR的流程如下所示。
// alloc idr... idr_init(idr); idr_preload(GFP_KERNEL); spin_lock(lock); id = idr_alloc(idr, ptr, start, end, GFP_NOWAIT); spin_unlock(lock); idr_preload_end(); if (id < 0) error; idr_remove(idr, id); idr_destroy(idr);
查询迭代
static inline void *idr_find(struct idr *idp, int id); void *idr_replace(struct idr *idp, void *ptr, int id); int idr_for_each(struct idr *idp, int (*fn)(int id, void *p, void *data), void *data); bool idr_is_empty(struct idr *idp);
- idr_find
- 根据指定的ID查找指针。
- idr_replace
- 相当于更新id对应的指针。
- idr_for_each
- fn函数的参数p将由迭代时的idr_layer指针代入, fn函数的data即是idr_for_each的最后一个参数,这里设计要求fn返回0表示成功,返回非0表示失败,最终idr_for_each如果全部执行成功返回0,否则就返回非0。
- idr_is_empty
- 该函数设计基于idr_for_each实现,只要idr中有一个元素,那么迭代就会调用fn,我们只需要设计一个fn始终返回1的函数,并调用idr_for_each即可。因为idr_for_each()在调用fn时发现返回非0,就会停止迭代并返回该值。
源码分析
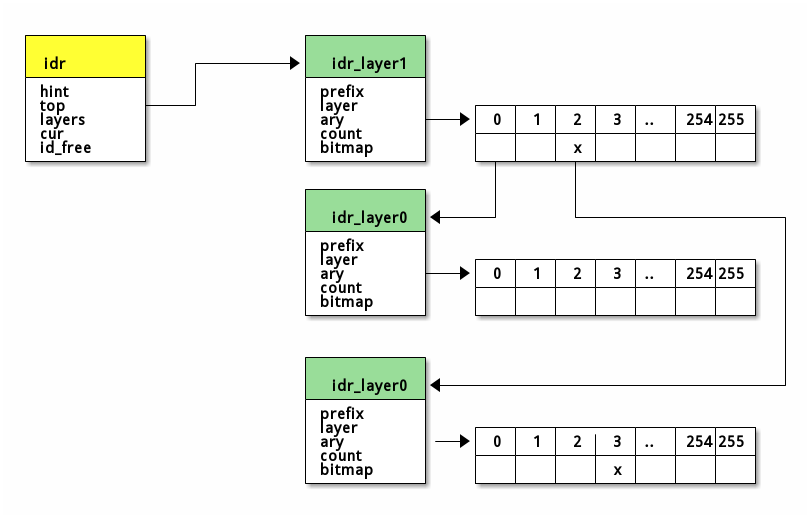
假设我们要查找0x515,0x515/0x256 = 2,表示位于第1层的编号2, 0x515%0x256 = 3,表示位于第0层的编号3,如下图所示。
数据结构
#define IDR_BITS 8 #define IDR_SIZE (1 << IDR_BITS) #define IDR_MASK ((1 << IDR_BITS)-1) struct idr_layer { int prefix; // 前缀,即高位,用于判断大范围 int layer; // 深度,到叶节点距离 struct idr_layer __rcu *ary[1<<IDR_BITS]; // 指向子节点 int count; // 引用计数,子节点个数 union { DECLARE_BITMAP(bitmap, IDR_SIZE); // ary使用情况 struct rcu_head rcu_head; }; };
struct idr { struct idr_layer __rcu *hint; // 最近使用的层 struct idr_layer __rcu *top; // 树根,深度最大的层 int layers; // 树高,最大层号加1 int cur; // 用于循环分配的当前位置 spinlock_t lock; int id_free_cnt; // 空闲链表的idr_layer数 struct idr_layer *id_free; // 空闲链表头 };
idr_alloc
1: int idr_alloc(struct idr *idr, void *ptr, int start, int end, gfp_t gfp_mask) 2: { 3: int max = end > 0 ? end - 1 : INT_MAX; 4: struct idr_layer *pa[MAX_IDR_LEVEL + 1]; 5: int id; 6: 7: might_sleep_if(gfp_mask & __GFP_WAIT); 8: 9: if (WARN_ON_ONCE(start < 0)) 10: return -EINVAL; 11: if (unlikely(max < start)) 12: return -ENOSPC; 13: 14: id = idr_get_empty_slot(idr, start, pa, gfp_mask, NULL); 15: if (unlikely(id < 0)) 16: return id; 17: if (unlikely(id > max)) 18: return -ENOSPC; 19: 20: idr_fill_slot(idr, ptr, id, pa); 21: return id; 22: }
- 3
- 确定整数区间,注意范围是[start, end)
- 4
- MAX_IDR_LEVEL具体有多大这里就不关心了,32位机上应该为4, \(2^{8\times4}\) 正好是32位机能表示的最大长度。
- 7
- 用于调试
- 14
- 分配ID,注意这里并没有指定最后一个参数layer_idr,因此不会调用get_from_free_list()从空闲链表分配
- 20
- 填充
idr_get_empty_slot
1: static int idr_get_empty_slot(struct idr *idp, int starting_id, 2: struct idr_layer **pa, gfp_t gfp_mask, 3: struct idr *layer_idr) 4: { 5: struct idr_layer *p, *new; 6: int layers, v, id; 7: unsigned long flags; 8: 9: id = starting_id; 10: build_up: 11: p = idp->top; 12: layers = idp->layers; 13: if (unlikely(!p)) { 14: if (!(p = idr_layer_alloc(gfp_mask, layer_idr))) 15: return -ENOMEM; 16: p->layer = 0; 17: layers = 1; 18: } 19: 20: while (id > idr_max(layers)) { 21: layers++; 22: if (!p->count) { 23: p->layer++; 24: WARN_ON_ONCE(p->prefix); 25: continue; 26: } 27: if (!(new = idr_layer_alloc(gfp_mask, layer_idr))) { 28: spin_lock_irqsave(&idp->lock, flags); 29: for (new = p; p && p != idp->top; new = p) { 30: p = p->ary[0]; 31: new->ary[0] = NULL; 32: new->count = 0; 33: bitmap_clear(new->bitmap, 0, IDR_SIZE); 34: __move_to_free_list(idp, new); 35: } 36: spin_unlock_irqrestore(&idp->lock, flags); 37: return -ENOMEM; 38: } 39: new->ary[0] = p; 40: new->count = 1; 41: new->layer = layers-1; 42: new->prefix = id & idr_layer_prefix_mask(new->layer); 43: if (bitmap_full(p->bitmap, IDR_SIZE)) 44: __set_bit(0, new->bitmap); 45: p = new; 46: } 47: rcu_assign_pointer(idp->top, p); 48: idp->layers = layers; 49: v = sub_alloc(idp, &id, pa, gfp_mask, layer_idr); 50: if (v == -EAGAIN) 51: goto build_up; 52: return(v); 53: }
- layer_idr
- 该参数表示从指定位置分配,也就是利用空闲链表。
- 13
- 如果没有根节点就会分配一个根节点层。
- 16-17
- p->layer是索引,很显然层数始终比索引要大1,如果一开始一层都没有,那么首次分配的层号为0。
- 20
- 当id超过当前idr所能表示的最大值时,就需要分配新的层,也就是增加树的高度。计算idr_max()也比较简单。 \(256^{layers} - 1\) ,这里为什么要减1呢,因为idr_max表示的是最大编号,而不是可表示的编号个数。
- 23
- 如果当前层无人使用,我们可以直接增大当前层的深度。很显然只有当idr中一层都没有的时候才会出现此种情况,否则我们一定是从叶节点成长起来的,也就是说只有刚刚建立的top才有机会执行这样的高效算法。
- 27
- 分配一个新的层
- 28-38
- 处理分配出错的情况,如果分配失败, top指向的idr_layer要全部重新初始化,并移到idp的空闲链表中。
- 39-45
- 初始化新分配的层。
- 39
- 将new设为p的父节点,这也是前面讲idr是从叶节点长起来的原因。
- 40
- 既然是从儿子长起来,就必然有人引用,引用计数要设置为1。
- 41
- 最大层号始终比层数小1。
- 42
- 设置prefix,这也是一个精妙的算法,
idr_layer_prefix_mask的算法很简单,就是
~idr_max(layer + 1),注意这里的layer是层号,因此调用idr_max()时要加1,如第0层mask为~0xFF,第1层mask为~0xFFFF,依次类推。很显然,prefix就是该层所能表示的范围之外的部分,之所以和id求与,是为了减少不必要的分支。 - 43-44
- 这也是一个精妙的设计,如果子节点的位图已经填满,那么表示new->ary[0]下起始已经没有可用的空间了,因此需要把父节点的对应位图填1,如果我们从上往下搜索,发现某个节点bitmap对应位为1,就表示该位对应以下的所有节点都被用光,极大的节省搜索时间。
- 45
- 将p指向new,也就是新的top,如此循环下去,直到树的高度满足要求,就停止循环。
- 47
- 用p去替换top,只要理解新分配的作为父节点,就能理解这里为什么直接替换top了。
- 49
- 从top指向的idr_layer树中获取ID号,分配路径记录到pa中,这个函数不会去增加树的高度,但是会在必要的时候分配新的层, idr_get_empty_slot()是从下往上长,而sub_alloc()则是生长必要的枝叶。
- 50-51
- 这是Linux内核中比较常见的一种做法,这里特别定义了
-EAGAIN的语义,首先要想一下为什么会出现这种情况,比较明显的一个例子是,树的高度虽然够了,能够足够表示starting_id,但是所有的ID已经被别人用光了,这种情况就不得不增加树的高度。 sub_alloc()返回-EAGAIN正是遇到了这种情况。
idr_layer_alloc
1: static struct idr_layer *idr_layer_alloc(gfp_t gfp_mask, struct idr *layer_idr) 2: { 3: struct idr_layer *new; 4: 5: if (layer_idr) 6: return get_from_free_list(layer_idr); 7: 8: new = kmem_cache_zalloc(idr_layer_cache, gfp_mask | __GFP_NOWARN); 9: if (new) 10: return new; 11: 12: if (!in_interrupt()) { 13: preempt_disable(); 14: new = __this_cpu_read(idr_preload_head); 15: if (new) { 16: __this_cpu_write(idr_preload_head, new->ary[0]); 17: __this_cpu_dec(idr_preload_cnt); 18: new->ary[0] = NULL; 19: } 20: preempt_enable(); 21: if (new) 22: return new; 23: } 24: 25: return kmem_cache_zalloc(idr_layer_cache, gfp_mask); 26: }
- 5
- 如果指定了layer_id,就从layer_id获取,也就是合理利用空闲链表。
- 8
- 从slab cache分配一个idr_layer,这个idr_layer_cache实际上是在start_kernel的时候创建的。正常情况下这里成功分配就应该返回了。
- 12
- 如果从slab分配失败,就尝试从PERCPU获取。
- 25
- 如果所有分配方式都失败了,就加上警告选项再从slab分配一次,如果这次失败,会体现出相应的错误信息。
sub_alloc
static int sub_alloc(struct idr *idp, int *starting_id, struct idr_layer **pa, gfp_t gfp_mask, struct idr *layer_idr) { int n, m, sh; struct idr_layer *p, *new; int l, id, oid; id = *starting_id; restart: p = idp->top; l = idp->layers; pa[l--] = NULL; while (1) { n = (id >> (IDR_BITS*l)) & IDR_MASK; m = find_next_zero_bit(p->bitmap, IDR_SIZE, n); if (m == IDR_SIZE) { l++; oid = id; id = (id | ((1 << (IDR_BITS * l)) - 1)) + 1; if (id > idr_max(idp->layers)) { *starting_id = id; return -EAGAIN; } p = pa[l]; BUG_ON(!p); sh = IDR_BITS * (l + 1); if (oid >> sh == id >> sh) continue; else goto restart; } if (m != n) { sh = IDR_BITS*l; id = ((id >> sh) ^ n ^ m) << sh; } if ((id >= MAX_IDR_BIT) || (id < 0)) return -ENOSPC; if (l == 0) break; if (!p->ary[m]) { new = idr_layer_alloc(gfp_mask, layer_idr); if (!new) return -ENOMEM; new->layer = l-1; new->prefix = id & idr_layer_prefix_mask(new->layer); rcu_assign_pointer(p->ary[m], new); p->count++; } pa[l--] = p; p = p->ary[m]; } pa[l] = p; return id; }
- 12
- 将l减1,就得到对应的层号。
- 14
- 该行很好理解,就是id在l层对应的编号。
- 15
- 从n开始找位图中为0的位置,前面已经提到,如果某个位图为1,就表该位置以下所有节点被用光了。
- 16-32
- 处理特殊情况:该层大于starting_id的位置都被占用,已经没有空闲位置可用。
- 17
- 层加层编号,向更高层进军,因为当前层已经被用光了。
- 19
- 增加id编号,让其进入其兄长区间,或者父亲区间。
- 21-23
- 如果新的id超过当前idr所能表示的范围,就更新starting_id,并返回
-EAGAIN,这样调用该函数的idr_get_empty_slot()就会去增加树高。 - 28-32
- 如果没有注释,恐怕没几个人能看得明白这是要干什么,这也是作者在这里秀技巧,如果相等,说明需要进入到上一层,这个时候只需要继续循环即可。如果不相等,说明不用进入上一层,这种情况需要重头开始。
- 34-36
- 这里也是在秀技巧,完全看不懂要干嘛。
- 38-41
- 检查有效性,如果l=0,那么就意味着已经抵达叶节点,可以退出循环。
- 43-53
- 如果ary[m]没有子节点,就需要分配一个层,并初始化。
- 52
- 保存当前层,减小层号。
- 53
- 进入子节点。
- 56
- 保存当前层。
- 57
- 返回实际找到的ID。
idr_fill_slot
static void idr_fill_slot(struct idr *idr, void *ptr, int id, struct idr_layer **pa) { rcu_assign_pointer(idr->hint, pa[0]); rcu_assign_pointer(pa[0]->ary[id & IDR_MASK], (struct idr_layer *)ptr); pa[0]->count++; idr_mark_full(pa, id); }
- hint
- 用于保存最近使用的层。
- pa[0]->ary[id & IDR_MASK]
- 用于保存所指定的指针。
static void idr_mark_full(struct idr_layer **pa, int id) { struct idr_layer *p = pa[0]; int l = 0; __set_bit(id & IDR_MASK, p->bitmap); /* * If this layer is full mark the bit in the layer above to * show that this part of the radix tree is full. This may * complete the layer above and require walking up the radix * tree. */ while (bitmap_full(p->bitmap, IDR_SIZE)) { if (!(p = pa[++l])) break; id = id >> IDR_BITS; __set_bit((id & IDR_MASK), p->bitmap); } }
- idr_mark_full
- 向上追溯标记占用情况,也就是字节点占用满了就标记其父节点对应的位,如果父节点也全部占用满了就标记爷爷对应的位,依次类推。