一致性算法
一致性算法
分布式系统
分布式系统是由一组通过网络进行通信、为了完成共同的任务而协调工作的计算机节点组成的系统。分布式系统的出现是为了用廉价的、普通的机器完成单个计算机无法完成的计算、存储任务。其目的是利用更多的机器,处理更多的数据。
分布式系统分为分布式计算(computation)与分布式存储(storage)。在能力扩展上,都是基于分片的思想实现,如计算用mapreduce,存储则每个节点存储一部分数据。在容错能力上,都是基于冗余的思想实现,以允许部分节点故障。但是很明显,引入冗余就需要解决一致性问题,强一致会破坏可用性,所以很多场景使用最终一致性。
拜占庭将军问题,不仅允许节点故障,还允许节点异常行为,是最复杂的分布式一致性问题。拜占庭将军问题由Paxos算法解决,后来的分布式一致性算法,都是Paxos的变种。
CAP理论:一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
- 一致性是指强一致性,即任何时刻数据一致
- 可用性是指任何时候可以读写成功
- 分区容错性是指系统可以容忍节点或网络分区故障
Paxos
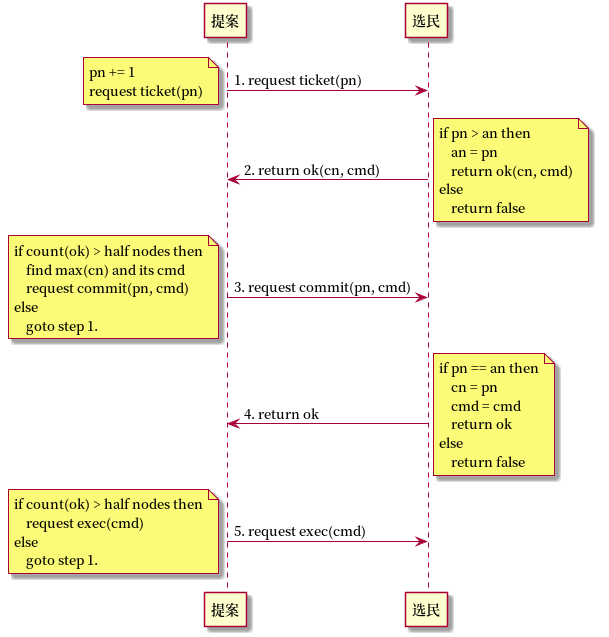
这是Basic Paxos,基于两阶段提交2PC实现,原理上和顺序锁类似。
- step1. 请求票pn,也就是请求锁的意思。
- step2. 更新票an,也就是更新锁。并返回票面值。
- step3. 拿到过半的票,就意味着加锁成功。接下来只需要选择最新的票面值提交。
- step4. 如果锁未被别人拿走,就可以更新票面值,并返回执行许可。
- step5. 如果收到足够执行许可,就可以执行命令。
这种Paxos存在活锁的可能,第3步加锁成功,并不能阻止锁被别人拿走,两个提案人可以相互破坏对方执行第4步。在实现上都是基于Multi Paxos实现,也就是两种状态的Paxos,即选主状态和领导状态。选主状态通过随机错开避免活锁,领导状态只有领导可以提案,也能避免活锁。
Raft
基本概念
- Leader
- 领导,任何时候只能有一个Leader,为客户端提供服务
- Follower
- 从节点,不主动发送请求,收到客户端请求会转发给Leader
- Candidate
- 候选节点,从节点在超时时间内没有收到心跳就会变为候选
- Term
- 任期号,一个任期只有一个Leader,每次选举产生一个任期
- RequestVote
- 请求投票,收到多数赞成后成为Leader
- AppendEntries
- 附加日志,Leader发送日志和心跳的机制
- Election Timeout
- 选举超时,该时间范围内没有收到心跳或追加日志,从节点就会发起选举
Raft协议的一些原则:
- 任何时候,系统最多只有一个有效Leader
- 所有请求由Leader处理,写入请求在收到多数响应后才会返回客户端
- Leader不修改日志,只做追加
- Leader包括最全的日志,日志只能从Leader流向从节点
- 如果日志再某个任期达成多数派,则以后的任期中日志一定存在
- 不依赖物理时序保证一致性,通过termId和logId保证
- 如果某个节点应用了日志(termId, logId),则在相同位置,其他节点一定会应用相同的日志
领导选举
- Candidate
- 超时时间内没有收到Leader日志或心跳,从节点变为候选节点
- 增加curTerm,设置超时
- 广播选举,等待响应
- 收到多数认可,变为Leader
- 收到Leader心跳,且term > curTerm,退为从节点
- 没有收到多数认可,也没有收到Leader心跳,增加curTerm,开始新一轮选举
- Folloer
- 收到候选的term小于自己的curTerm,不投票
- 如果还没有投票,且候选的(lastTermId, lastLogId)至少和自己一样新,投票给候选
- 一个任期只能投一票
- 分裂问题
如果一个从节点被网络分裂,它会不断发起选举,Term会越来越大。当网络合并时,它的选举会广播出去,导致别人更新Term变成从节点,由于它的日志不是最新,并不会成为Leader,虽然最终会决出新的Leader,但是被这种隔离过的从节点扰乱原有集群是没必要的。
PreVote可以避免集群被扰乱,预投票的目的是为了避免盲目增加TermId,候选者通过PreVote确认大多数同意发起选举时才会增加TermId。
从节点对PreVote赞成的条件:
- 没有收到有效Leader的心跳,至少有一次选举超时
- 候选者的日志足够新
如果一个Leader被网络分裂,剩下的网络可能会决出新的Leader,当孤立Leader网络接通时,会收到新Leader的心跳,由于新Leader的(termId, logId)更新,孤立Leader自动退为从节点。在Leader被孤立期间,孤立Leader并不知道有新的Leader,读取操作可能会读到老的数据。
为了解决从孤立Leader读到老的数据,可以引入region leader来解决stale read问题。如果出现region leader和真正leader不一致的情况, region leader有lease过期时间,当lease过期时,新的region leader一定在多数派产生。
- region leader在多数,old leader在多数,正常读写
- region leader在多数,old leader在少数,请求不会落到少数,正常读写
- region leader在少数,old leader在多数,请求都落到少数,由于所有新的写都不会成功,所以不会读到老数据,事实上因为少数派不会选出新的Leader,根本无法执行读写操作
- region leader在少数,old leader在少数,请求都落到少数,由于所有新的写都不会成功,所以不会读到老数据
日志复制
Leader在发送日志复制时,会带上前一个日志,如果从节点匹配前一个日志就会写入,否则Leader会不断减少索引位置并重试。从节点会删除匹配日志之后的所有日志,并追加Leader的日志。
Leader流程:
- 接收客户端请求,持久化本地日志
- 将日志分发出去,Leader发送日志会带上前一条日志(termId, logId)
- 如果达成多数就提交,返回给客户端
从节点流程:
- 比较新的日志的termId是否小于自身curTerm,如果小于说明日志无效,拒绝
- 对比前一条日志(termId, logId),如果没有(termId, logId)日志,返回缺少日志,让Leader减少索引重试,如果不匹配,就删除自己的日志,返回缺少日志,让Leader减少索引重试
如果宽泛的讲,达成多数派的日志就一定认为是提交的,是不严谨的。任何日志都有(termId, logId)属性,只有当这些日志在同一个任期termId达成多数派,才会被提交。如果(termId, logId)在termId时没有形成多数派,由于leader频繁变更,在termId+n的时候才由leader分发形成多数派,是不能保证被提交的,因为如果此时leader挂了,新选出的leader可以没有(termId, logId),而是拥有其他更新的日志(termId+x, logId+y)。
日志可以生成快照,生成快照以后,就可以删除之前的快照和日志。快照会造成IO压力,但快照之后可以清理非必要的日志以缓解空间压力,所以要合理控制快照时间间隔。
Zab
ZooKeeper使用ZAB(ZooKeeper Atomic Broadcast)实现一致性,全称为原子广播协议。 ZK使用单一主进程处理客户端请求,使用ZAB协议将服务器状态广播到从节点,ZAB保证变更按顺序处理。 Zab的Leader被动接收从节点的心跳,一段时间没有收到超过半数从节点的心跳,就会退为Looking状态(类似Candidate),所有从节点也会放弃该Leader,并切换到Looking状态,开始选举。如果Leader挂了,从节点也会发现心跳不成功,从而切换到Looking状态。
在Zab中,事务由ZXId标识,ZXId高32位为epoch,低32位为递增计数器,epoch用来区分不同的Leader周期。
选举:Leader的ZXId必为最新。在处理投票时,先检查ZXId,如果ZXId相同,会检查sid(服务器Id),所以不论怎样都只会出现一个Leader。
同步:由Leader发起同步,将数据同步给从节点。同步有三种策略。
- SNAP,从节点信息太老时使用
- DIFF,同步Follower.lastZXID到Leader.lastZXID之间的数据
- TRUNC,当Follower.lastZXID大于Leader.lastZXID时让从节点丢弃数据
广播:Leader选出之后,由Leader广播请求提交。这一点和Raft一样理解即可。